Prompt caching
API-level exposure of the inference engine's KV cache: you pay once for the static prefix (tool defs, system prompt, project context) then read it back at 0.1x input price on all following requests. Claude Code shows 92% hit-rate and -81% cost on a session. It is not a toggle, it is an architectural discipline.
Prompt caching
TL;DR
API-level exposure of the inference engine's KV cache: you pay once for the static prefix (tool defs, system prompt, project context) then read it back at 0.1x input price on all following requests. Claude Code shows 92% hit-rate and -81% cost on a session. It is not a toggle, it is an architectural discipline.
The historical problem
An LLM agent sends back the FULL conversation history on every turn: system prompt, tool definitions, project context already read 3 turns ago, plus the new messages. Without a server-side cache, everything is retokenized and re-attended every turn.
Order of magnitude: a 20k token system prompt over 50 turns = 1M tokens of redundant compute, billed at full price, producing zero new value. On a production agent fleet, it is often the first cost line.
The fix existed server-side for a long time through the kv cache (vLLM PagedAttention, SGLang RadixAttention). But as long as the API did not expose it, the client still paid for the recompute. Anthropic (August 2024) then OpenAI (October 2024) opened this mechanism to the end user, with explicit pricing.
How it works
Static vs dynamic split
Every agent request has two parts:
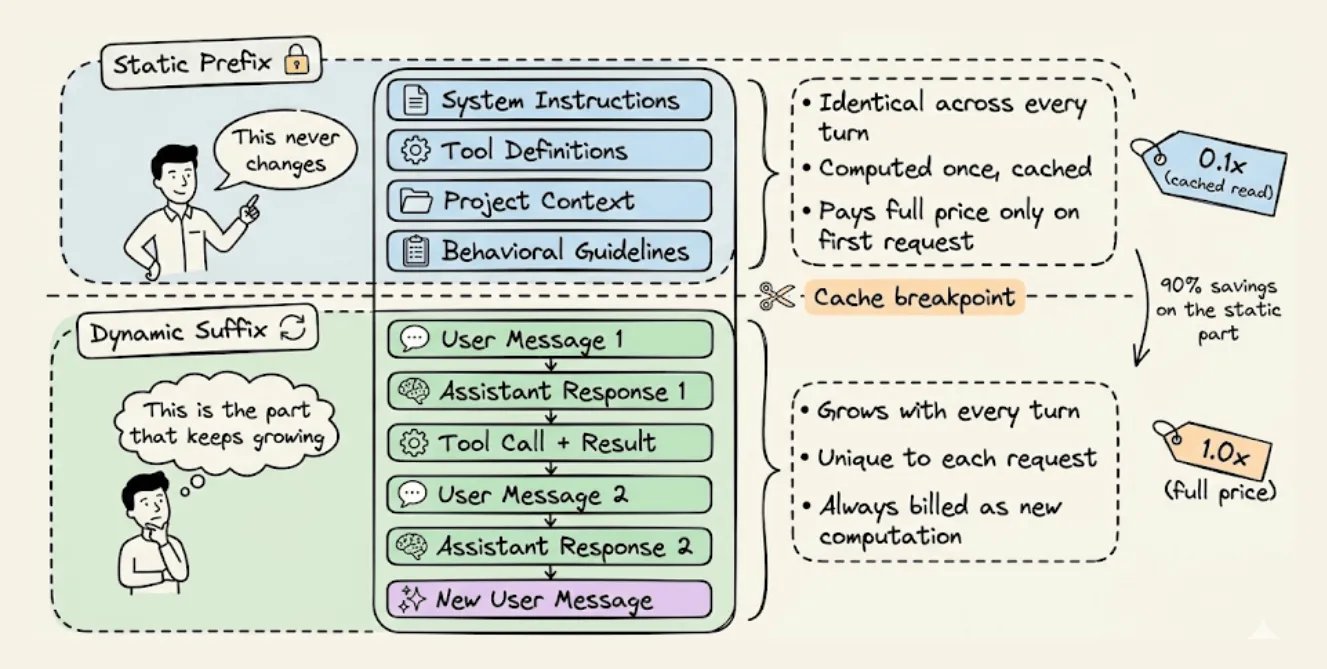
- Static prefix identical every turn: system instructions, tool definitions, project context, behavioral rules
- Dynamic suffix that grows: user messages, assistant answers, tool outputs, terminal observations
This split is what makes caching possible. The infra stores the mathematical state of the prefix and lets following requests with the exact same prefix read it from memory instead of recomputing.
The 2 inference phases (reminder)
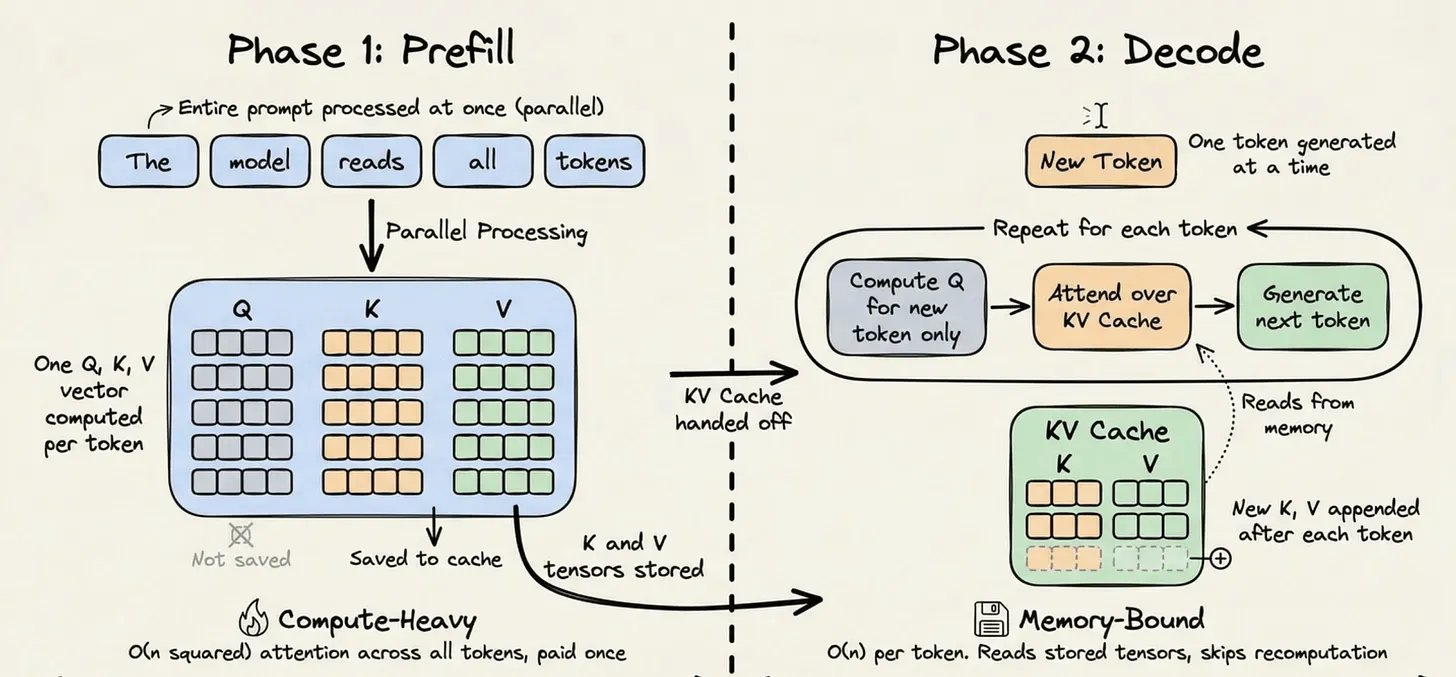
- Prefill phase: processes the whole input prompt. Dense matmul on all tokens to build the internal representation. Compute-bound, expensive.
- Decode phase: generates tokens one by one. Each new token attends to the past. Memory-bound.
For each token in prefill, the Transformer computes 3 vectors: Query, Key, Value. K and V of a token only depend on tokens before it. Once computed, they never change. See kv cache for details.
Hash-based caching
Without cache: K/V thrown away after each request, full recompute on the next call.
With cache:
- K/V of the static prefix are persisted on the inference server, indexed by a cryptographic hash of the token sequence
- New request comes in -> hash the prefix -> if match, tensors loaded from memory, prefill skipped for these tokens
- Only the new tokens (dynamic suffix) are prefilled
Complexity: from O(n^2) per generated token to O(n). On a 20k token prefix repeated over 50 turns, huge reduction.
Economics (Anthropic, April 2026)
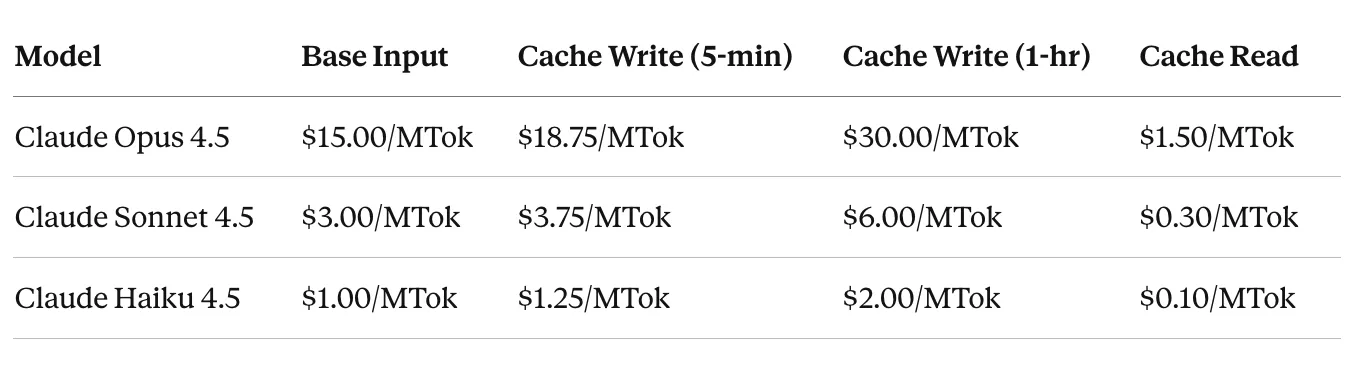
- Cache read: 0.1x base input price = -90% per cached token
- Cache write: 1.25x = +25% to write the K/V tensors
- Extended cache (1h TTL): 2.0x
The math only works if the hit-rate stays high. Typical break-even: >=2 reads to amortize the write.
Claude Code: 92% hit-rate case study
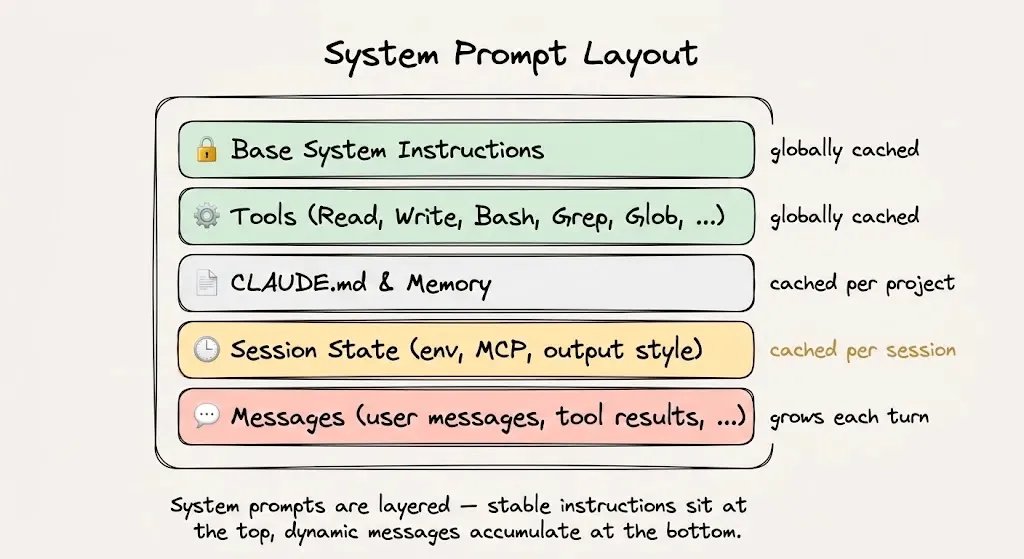
30 min coding session with Claude Code:
- Minute 0: system prompt + tool defs + CLAUDE.md > 20k tokens. All new = most expensive moment of the session, but paid once.
- Min 1-5: Explore Subagent navigates the code, greps, reads files. Appends to the dynamic suffix. The 20k prefix -> cached at $0.30/MTok instead of $3.00/MTok.
- Min 6-15: Plan Subagent receives a summary brief (not the raw output, avoids bloating). Produces a plan. Every turn re-reads the prefix from the cache. Hit rate > 90%. Each hit resets the TTL (cache stays warm).
- Min 16-25: Changes, more tool calls, more terminal output. Hundreds of thousands of tokens processed, but the 20k prefix stays in cache.
- Min 28:
/costshows 2M tokens total. Without caching: $6. With 92% hit-rate: 1.84M in cache reads -> $1.15. -81% on the task.
Hash-based caching fragility
The most counter-intuitive thing: "1 + 2 = 3" hit, but "2 + 1" is a cache miss.
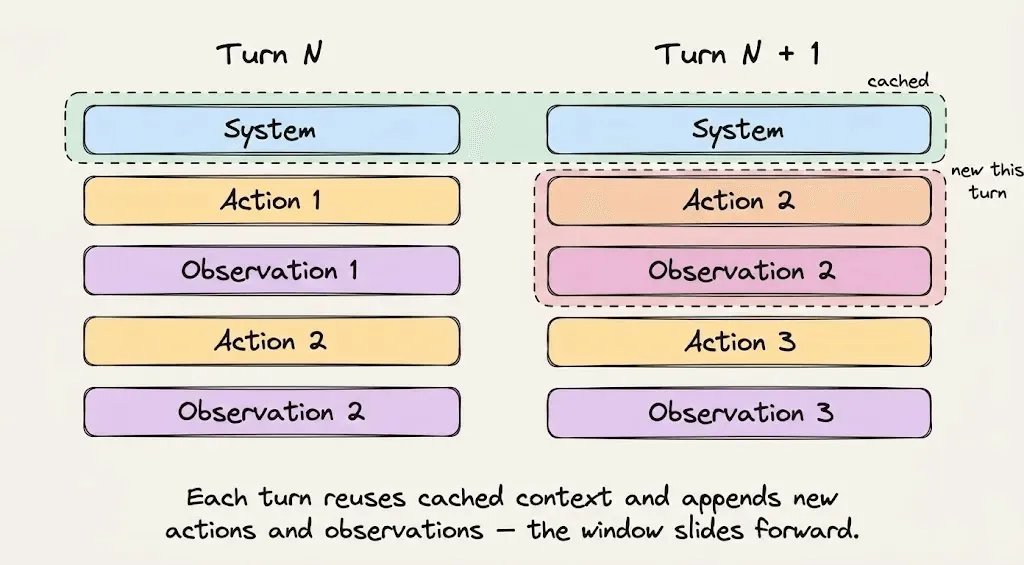
The infra hashes the full sequence from the start. The smallest change (even the order of 2 elements) changes the hash and invalidates the full prefix -> full-price recompute.
Real production examples that broke the cache:
- A timestamp injected in the system prompt -> unique hash every request
- A JSON serializer sorting tool schema keys differently between requests -> invalidation
- An AgentTool whose params were updated mid-session -> wipe of the 20k cached tokens
3 rules that follow from this:
- Do not modify tools during a session. Tool defs are part of the cached prefix. Add or remove a tool and you invalidate everything downstream.
- Never switch models mid-session. Caches are model-specific. Switching to a cheaper model mid-conversation = full rebuild.
- Never mutate the prefix to update state. Instead of editing the system prompt, Claude Code appends a reminder tag to the next user message to keep the prefix intact.
Relevance today (2026)
Prompt caching has become table stakes for any serious agent stack:
- Anthropic: auto-caching on the API, breakpoint automatically advanced as the conversation grows. Gemini 2.5 and OpenAI also have their version.
- 1M context Claude makes prompt caching even more critical: without it, an agent with full context pays $3/MTok x 1M = $3 per turn.
- Client ecosystem: frameworks (LangGraph, Anthropic SDK, Vercel AI SDK) support explicit or auto cache breakpoints more and more.
- Cross-session cache: Anthropic introduced the 1h-TTL (2.0x write) which keeps the cache warm across distinct users -> critical for multi-tenant SaaS.
- Tension with context compression: you can no longer aggressively summarize history every turn without breaking the cache. New primitive: cache-safe forking (see next section).
Question to ask: is your agent stack designed around caching, or is caching an add-on ? If it is the latter, you leave 70-90% of your margin on the table.
Apply the pattern to your own agent
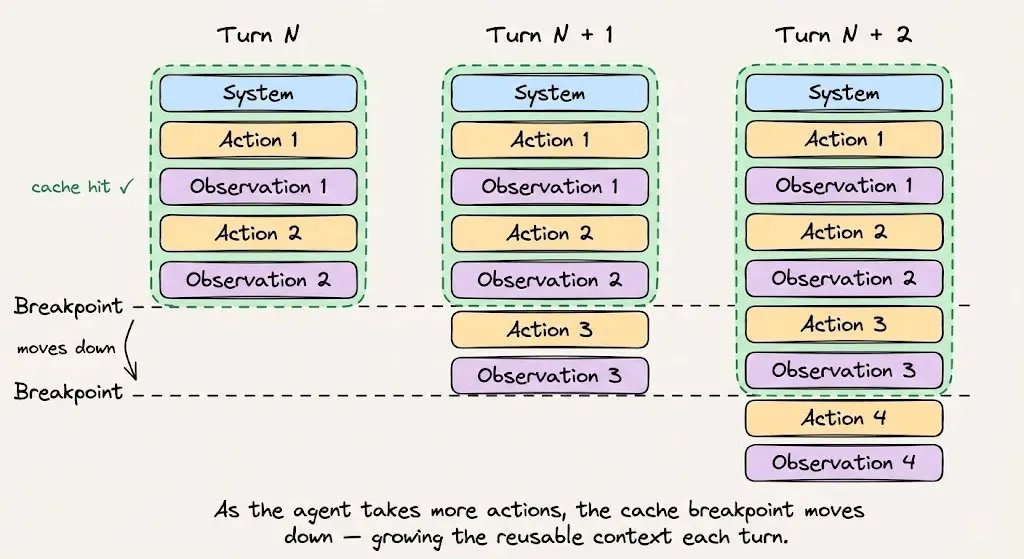
Order of an optimized agent prompt:
- System instructions + behavioral rules first. Immutable during the session.
- Tool definitions loaded upfront. No addition or removal mid-session.
- Retrieved context / reference docs next. Stable for the session duration.
- Conversation history + tool outputs last = dynamic suffix.
Cache-safe forking for compaction
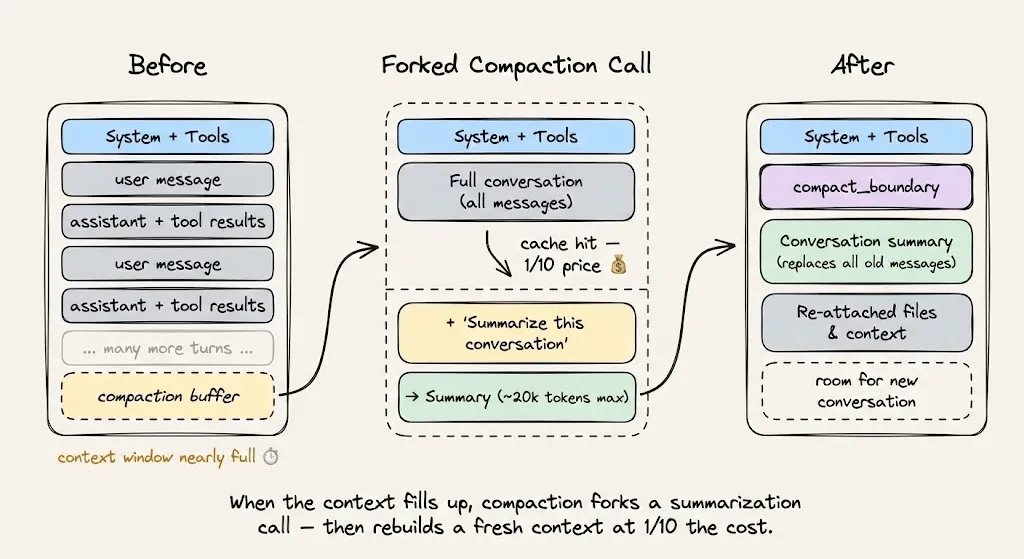
When approaching the context limit:
- Keep the same system prompt, tools, conversation history
- Append the compaction instruction as a new message
- The prefix stays hit, only the new instruction is billed
Anti-pattern: rewriting the summarized conversation = new prefix = full miss.
Monitoring
3 fields to track in every API response:
cache_creation_input_tokens: written to the cachecache_read_input_tokens: served from the cacheinput_tokens: processed without caching
Cache efficiency = cache_read / (cache_read + cache_creation).
Track it like you track uptime. Alert if hit-rate drops (signals a prefix stability regression).
Critical questions
- Why an exact hash and not a more tolerant prefix match ? Answer: latency. Hash = O(1) lookup. Fuzzy prefix matching = trade-off infra folks did not want to make.
- If my agent has 100 simultaneous users with the same system prompt, do they share the cache ? Answer: depends on the provider (Anthropic yes on the static prefix, isolation by org).
- Explicit cache breakpoint vs auto: when to use which ? Auto for most cases, explicit when you have edge cases (multiple static segments) or need fine control.
- How many breakpoints max per prompt ? Anthropic: 4 in April 2026. Use them strategically (e.g.: 1 = tools, 2 = system, 3 = retrieved docs, 4 = rolling suffix).
- When is the 1h extended cache worth it ? Break-even: write cost 2.0x vs 1.25x -> the gains on multiple reads within 1h must exceed the diff. Typically yes as soon as >3 users hit the same prefix within the hour.
- If the TTL expires (5 min by default), do we need to rebuild ? Yes but every hit resets the TTL -> an active agent stays warm indefinitely.
- How to test caching impact in dev without budget ? Watch
cache_read_input_tokensin API responses, no need for a perf benchmark.
Production pitfalls
- Timestamp in the system prompt: silent killer. Every request = unique hash = 0% hit rate. First thing to audit when cache efficiency < 50%.
- Non-deterministic JSON schemas: serializer reordering keys -> hash changes. Force alpha sort of keys.
- Dynamically generated tool defs: if you build your tools from a registry that changes order based on registration order -> invalidation. Freeze the order at startup.
- Wrongly placed breakpoint: if the cache breakpoint falls in the middle of the dynamic suffix, the boundary moves every turn -> miss. Place the breakpoint at the end of the static zone.
- Mid-session model switching: a router flipping Haiku -> Sonnet after N turns breaks the whole cache.
- Mutating the system prompt to update state (e.g.: "user is now in premium mode") -> invalidates. Pass the info in the next user message.
- Cold start: first request without cache = expensive. Budget it separately for cost-per-session metrics.
- Naive compaction: replacing history with a summary = new prefix = miss. Use cache-safe forking.
- Cache invalidation from a middleware bug: a middleware adding a header logging the request-id to the prompt body = permanent wipe. To audit.
- Multi-region: caches are region-specific. A load balancer that shuffles across regions breaks the hit rate.
Alternatives / Comparisons
Providers (April 2026)
| Provider | Auto cache | Explicit breakpoint | Read discount | TTL default | Note |
|---|---|---|---|---|---|
| Anthropic (Claude) | Yes | Yes (max 4) | 0.1x | 5 min, extended 1h (2x write) | Most mature, clearest API |
| OpenAI | Auto only | No | 0.5x GPT-4o, 0.25x GPT-4o-mini | 5-10 min | Less control, less aggressive discount |
| Google Gemini | Yes (explicit + implicit) | Yes | ~0.25x | 5 min | Implicit by default since 2.5 |
| xAI Grok | Yes | No | 0.25x | 5 min | More recent |
| Amazon Bedrock | Depends on the model | Yes on Claude | Inherits from provider | - | Exposes the feature upstream |
Self-hosted side
For self-hosted stacks, caching is handled by the inference server (not the API):
- vLLM: PagedAttention + automatic prefix sharing. See vllm.
- SGLang: RadixAttention, excellent on tree-based prefix sharing (agents with branches).
- TGI (HuggingFace): partial prefix caching.
- LMCache: tiered (GPU -> CPU RAM -> disk) for massive contexts.
Versus alternatives
- Context compression (LLMLingua, summarization): reduces token count but breaks the cache because it changes the prefix. Combine carefully (compress once then keep stable).
- RAG retrieval every turn: if retrieved docs change every turn, the prefix is not stable -> no cache. Strategy: retrieve in batch at session start, frozen for the rest.
- Fine-tuning: replaces the stable context with model-internal knowledge. Removes the need for caching but expensive upfront.
Mini-lab
To create: /lab prompt-caching
Learning goals:
- Build a tool-use agent with the Anthropic SDK
- Measure hit rate without a cache break-point
- Add explicit cache_control on system prompt and tool defs
- Compare latency + cost on 20 turns with and without cache
- Intentionally break the cache (timestamp, key reorder) and observe the impact
- Bonus: implement cache-safe compaction (fork with new instruction)
Further reading
- Source article: Prompt caching in LLMs, clearly explained (@_avichawla, April 2026)
- Anthropic prompt caching docs
- OpenAI prompt caching
- Gemini context caching
- vLLM paper "PagedAttention" (Kwon et al, 2023) - technical base of production KV cache: https://arxiv.org/abs/2309.06180
- SGLang paper "RadixAttention" (Zheng et al, 2024) - tree-based prefix sharing: https://arxiv.org/abs/2312.07104
- kv cache for the fundamentals
- [[../05-ai-agents/README]] for cache-friendly agent design