C'est quoi les tokens (et pourquoi ça te coûte cher)
Les tokens, c'est la monnaie des LLMs. Comprends comment ça marche et tu comprendras ta facture, les limites et les bizarreries de l'IA.
Tu reçois ta facture Claude. 47€. Pour quoi exactement?
Des tokens. C'est la seule unité qui compte quand tu utilises un LLM. C'est ce que tu paies, c'est ce qui limite la mémoire du modèle, et c'est la source de pas mal de comportements bizarres.
Andrej Karpathy (co-fondateur d'OpenAI, ex-Tesla AI) résume bien: "Tokenization is at the heart of much weirdness of LLMs." Pourquoi un LLM galère avec l'arithmétique? Les tokens. Pourquoi il est moins bon en français qu'en anglais? Les tokens. Pourquoi il peut pas épeler un mot à l'envers? Encore les tokens.
Comprendre les tokens, c'est comprendre comment un LLM voit le monde.
L'intuition
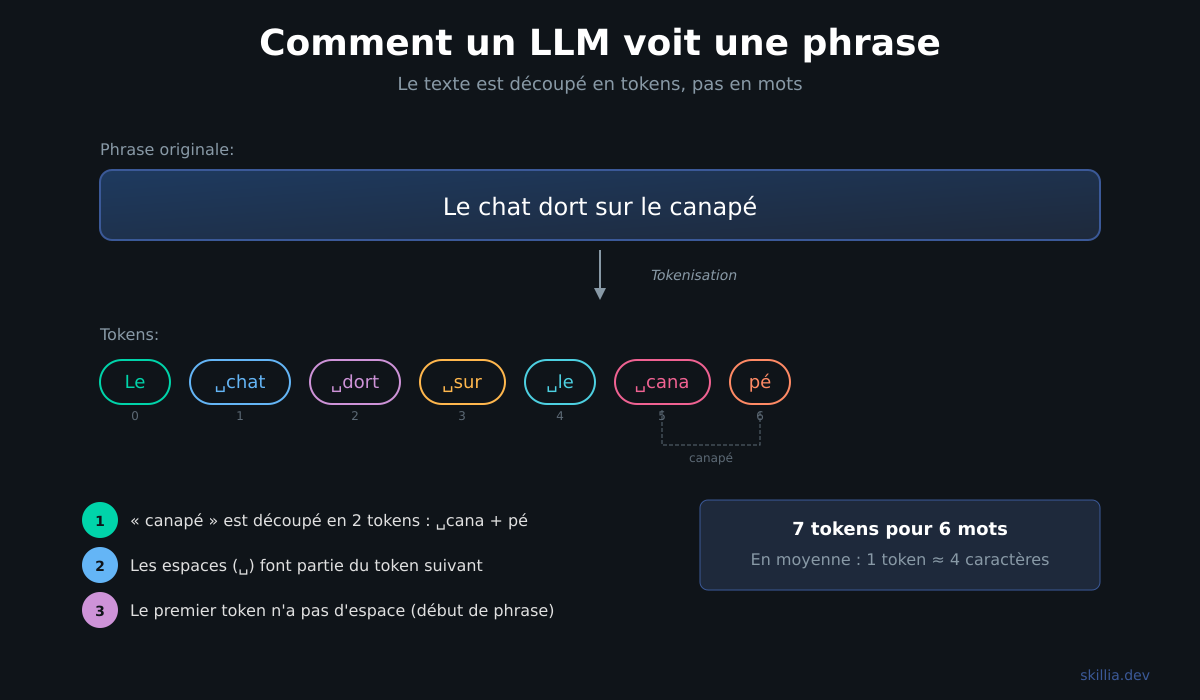
Tu lis cette phrase mot par mot. Un LLM ne fait pas ça.
Il découpe le texte en morceaux appelés tokens. Un token, c'est parfois un mot entier, parfois un bout de mot, parfois juste un caractère.
"Bonjour" → 1 token. "Anticonstitutionnellement" → 4 tokens: "Anti", "constitu", "tion", "nellement". "Hello world" → 2 tokens. "🎉" → 1 token.
En anglais, la règle approximative c'est 1 token ≈ 4 caractères, soit environ 0.75 mots. En français, les mots sont plus longs, donc le ratio est un peu moins bon.
Pourquoi découper comme ça au lieu de prendre des mots entiers? Parce que la langue est infinie. Il y a des noms propres, des mots composés, des fautes de frappe, du code, des emojis. Un vocabulaire de mots entiers serait gigantesque et ne couvrirait jamais tout.
Les tokens, c'est un compromis. Assez gros pour capturer du sens, assez petits pour couvrir n'importe quel texte.
Comment ça marche: le BPE
L'algorithme derrière la tokenisation de presque tous les LLMs modernes s'appelle BPE (Byte Pair Encoding). Il a été inventé en 1994 par Philip Gage pour la compression de données, puis adapté pour les LLMs.
Le principe est simple.
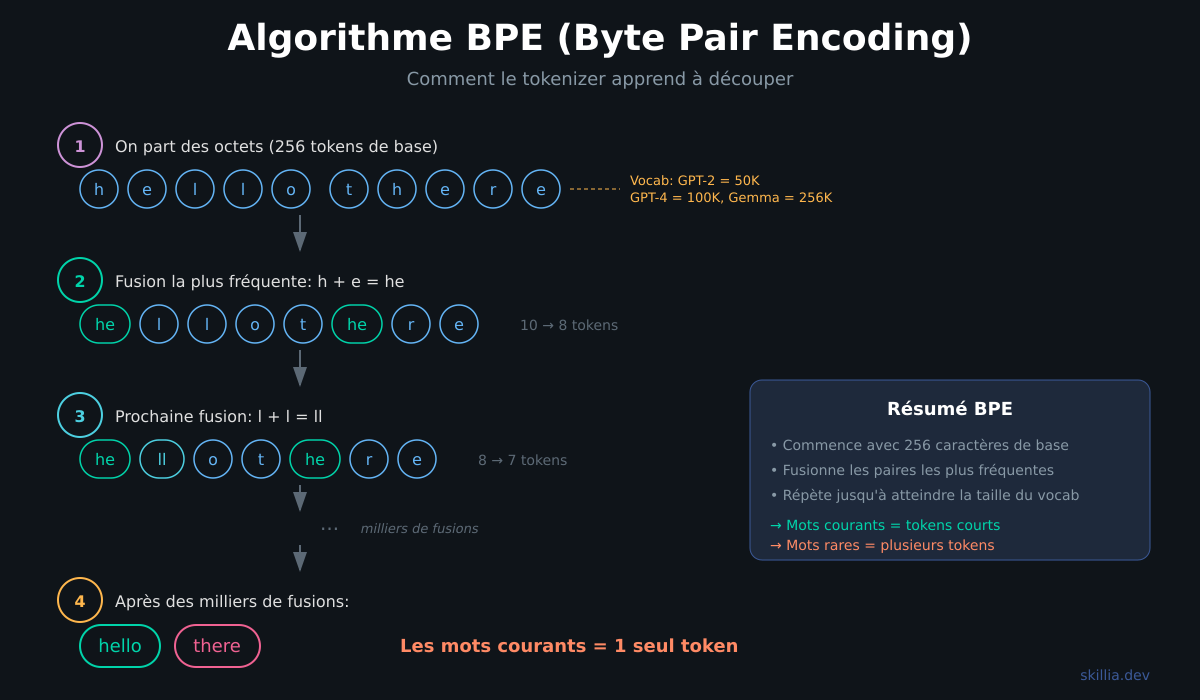
On part des caractères individuels. Le vocabulaire de base contient 256 tokens, un pour chaque octet possible.
On compte les paires. On regarde tout le texte d'entraînement et on cherche quelles paires de tokens apparaissent le plus souvent. Par exemple, "t" suivi de "h" apparaît tout le temps en anglais.
On fusionne la paire la plus fréquente. "t" + "h" devient un nouveau token "th". On l'ajoute au vocabulaire.
On répète. "th" + "e" → "the". "in" + "g" → "ing". Et ainsi de suite, des milliers de fois, jusqu'à atteindre la taille de vocabulaire souhaitée.
C'est pour ça que les mots courants deviennent souvent un seul token ("the", "and", "Bonjour") alors que les mots rares sont découpés en plusieurs morceaux.
Sebastian Raschka a implémenté BPE from scratch dans un notebook très clair si tu veux voir le code.
Chaque modèle a son propre tokenizer
Un détail important: le même texte ne donne pas les mêmes tokens selon le modèle.
GPT-2 avait un vocabulaire de 50 257 tokens. GPT-4 est passé à 100 258. Les modèles Gemma de Google utilisent 256 000 tokens.
Plus le vocabulaire est grand, plus les mots courants sont représentés en un seul token. Mais ça augmente la taille du modèle.
Concrètement, si tu comptes les tokens avec le tokenizer d'OpenAI (tiktoken), le résultat sera différent de celui d'Anthropic. Quand tu estimes tes coûts, utilise toujours le tokenizer du modèle que tu utilises.
Le problème des langues
C'est là que ça devient intéressant pour nous, francophones.
Les LLMs sont entraînés principalement sur du texte anglais. Le BPE apprend ses fusions sur ces données. Résultat: les mots anglais courants sont souvent un seul token, alors que les mots français, arabes ou japonais sont découpés en plus de morceaux.

"Hello" → 1 token. "Bonjour" → 1 token (mot assez courant pour être fusionné). "こんにちは" (konnichiwa) → 3-4 tokens.
Une étude a montré que certaines langues nécessitent 2 à 10 fois plus de tokens que l'anglais pour exprimer la même chose.
Ça veut dire quoi concrètement? Que tu paies plus cher pour la même tâche en japonais qu'en anglais. Que le context window se remplit plus vite. Que la qualité peut baisser plus vite sur les conversations longues.
En français, l'écart est modéré (on partage beaucoup de racines latines avec l'anglais), mais il existe. Un texte français consomme en moyenne 10 à 20% de tokens de plus que son équivalent anglais.
Pourquoi les tokens expliquent les bizarreries des LLMs
Karpathy liste les problèmes directement causés par la tokenisation:
L'arithmétique. Le nombre "380" peut être un seul token, ou "3", "80", ou "38", "0". Le modèle ne voit pas des chiffres, il voit des blocs arbitraires. C'est comme si on te demandait de faire 380 + 127 mais en te montrant "tro" + "is cent qua" + "tre-vingt" + " plus " + "cent vi" + "ngt-sept". Pas évident.
Épeler à l'envers. Tu demandes "épelle TOKYO à l'envers", le LLM galère. Parce que "TOKYO" est probablement un seul token. Il ne voit pas les lettres individuelles T-O-K-Y-O.
Les langues non-latines. Plus le texte est fragmenté en petits tokens, plus le modèle a du mal à capturer le sens. C'est un des facteurs qui explique que les LLMs sont meilleurs en anglais.
Le code Python. Les indentations en Python (espaces en début de ligne) étaient mal tokenisées dans GPT-2. Résultat: le modèle était mauvais en Python. GPT-3.5+ a corrigé ça en ajustant le tokenizer.
En pratique: comprendre ta facture
Tu paies deux choses quand tu utilises un LLM via API: les tokens en entrée (ton prompt, le contexte) et les tokens en sortie (la réponse du modèle). L'output coûte systématiquement plus cher, souvent 5x plus.
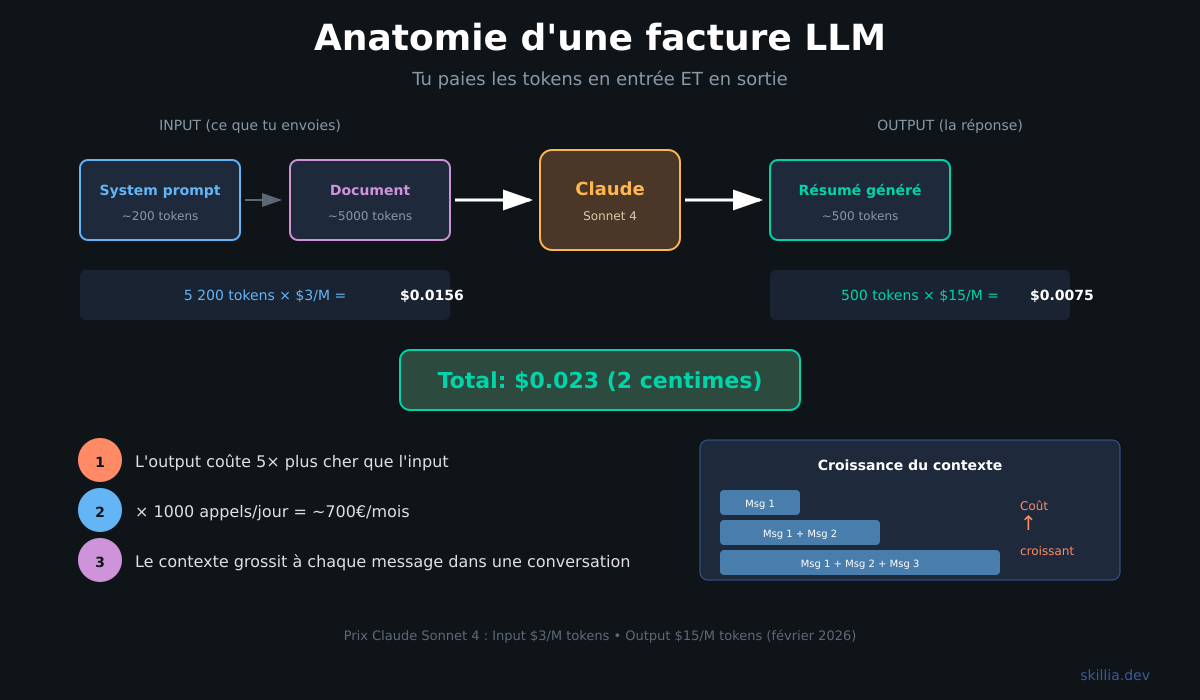
Prenons un exemple concret. Tu veux que Claude résume un document de 10 pages.
Document envoyé: environ 5 000 tokens (input). System prompt: environ 200 tokens (input). Résumé généré: environ 500 tokens (output).
Avec Claude Sonnet 4.5 ($3 input / $15 output par million de tokens): l'input coûte $0.0156, l'output $0.0075. Total: environ 2 centimes.
Ça paraît rien. Mais si ton agent fait 1 000 appels par jour, ça fait $23/jour, soit environ 700€/mois.
Et attention au piège: dans une conversation, chaque message précédent est renvoyé au modèle. Le contexte grossit à chaque échange. Au message 20, tu envoies potentiellement 10 000 tokens de contexte à chaque appel.
En pratique: compter et optimiser
Compter les tokens en TypeScript
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic();
const count = await client.messages.countTokens({
model: "claude-sonnet-4-5-20250929",
messages: [{ role: "user", content: "Ton message ici" }]
});
console.log(`${count.input_tokens} tokens`);
Règle rapide si tu as pas envie d'appeler l'API: divise le nombre de caractères par 4. C'est pas précis mais ça donne un ordre de grandeur.
Réduire les coûts
Prompt caching. Si tu envoies le même system prompt à chaque appel, Anthropic le met en cache. Tu paies 10% du prix à partir du deuxième appel.
const response = await anthropic.messages.create({
model: "claude-sonnet-4-5-20250929",
max_tokens: 1024,
system: [{
type: "text",
text: longSystemPrompt,
cache_control: { type: "ephemeral" }
}],
messages
});
Résumer le contexte. Au lieu de garder tous les messages d'une conversation, résume les anciens et garde seulement les 10 derniers.
const summary = await summarize(conversation.slice(0, -10));
const messages = [
{ role: "system", content: `Résumé: ${summary}` },
...conversation.slice(-10)
];
Choisir le bon modèle. Haiku pour les tâches simples (classification, extraction). Sonnet pour le quotidien. Opus quand tu as vraiment besoin du meilleur raisonnement. Un appel Haiku coûte 5x moins qu'un appel Sonnet pour la même quantité de tokens.
Limiter l'output. Si tu as besoin d'une réponse courte, dis-le au modèle avec max_tokens.
Les pièges
Le context qui explose. Dans un agent qui fait des appels en boucle, le contexte peut grossir sans que tu t'en rendes compte. Mets un mécanisme de troncature ou de résumé.
Les espaces comptent. " red" (avec espace avant) et "Red" (début de phrase) sont des tokens différents. C'est pour ça que le formatage de tes prompts a un impact.
Les tokens spéciaux. Les modèles utilisent des tokens spéciaux invisibles pour marquer le début/fin de conversation, les rôles (user, assistant), etc. Tu les vois pas mais tu les paies.
Le "SolidGoldMagikarp" bug. En 2023, des chercheurs ont découvert que certains tokens dans le vocabulaire de GPT n'apparaissaient presque jamais dans les données d'entraînement. Quand le modèle tombait sur ces tokens "fantômes", il buggait complètement. Un rappel que la tokenisation n'est pas parfaite.
En résumé
Les tokens, c'est la façon dont un LLM voit le texte: pas en mots, mais en morceaux appris statistiquement par l'algorithme BPE. C'est ce que tu paies, c'est ce qui limite la mémoire du modèle, et c'est la source de beaucoup de comportements inattendus.
Comprendre les tokens, c'est comprendre pourquoi ta facture est ce qu'elle est, pourquoi le français coûte un peu plus cher que l'anglais, et pourquoi ton LLM galère à faire des maths.
Pour voir comment les tokens s'intègrent dans le fonctionnement complet d'un LLM, c'est expliqué dans notre guide C'est quoi un LLM.
Sources: