What are tokens (and why they cost you money)
Tokens are the currency of LLMs. Understand how they work and you'll understand your bill, the limits, and the quirks of AI.
You get your Claude bill. 47 euros. For what exactly?
Tokens. It's the only unit that matters when you use an LLM. It's what you pay for, it's what limits the model's memory, and it's the source of quite a few weird behaviors.
Andrej Karpathy (OpenAI co-founder, ex-Tesla AI) puts it well: "Tokenization is at the heart of much weirdness of LLMs." Why does an LLM struggle with arithmetic? Tokens. Why is it worse in French than in English? Tokens. Why can't it spell a word backwards? Tokens again.
Understanding tokens means understanding how an LLM sees the world.
The intuition
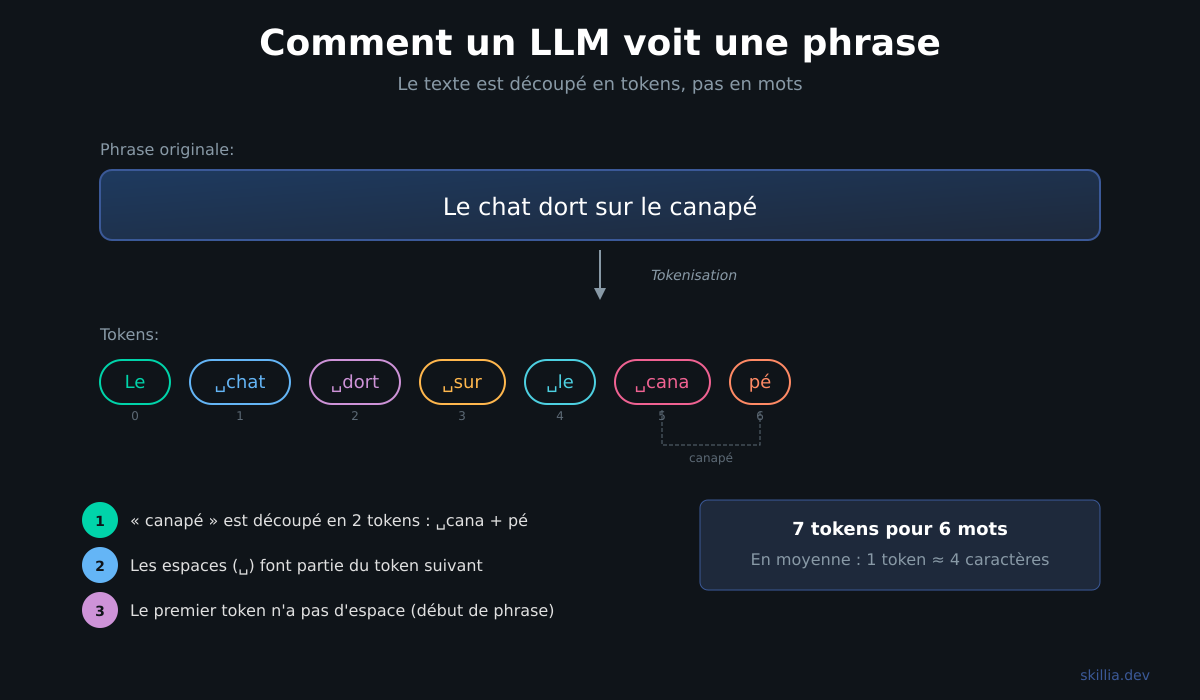
You read this sentence word by word. An LLM doesn't.
It splits text into chunks called tokens. A token is sometimes a whole word, sometimes a piece of a word, sometimes just a character.
"Hello" → 1 token. "Unconstitutionally" → 4 tokens: "Un", "constitu", "tion", "ally". "Hello world" → 2 tokens. "🎉" → 1 token.
In English, the rough rule is 1 token ≈ 4 characters, or about 0.75 words. In French, words are longer, so the ratio is slightly worse.
Why split like this instead of using whole words? Because language is infinite. There are proper nouns, compound words, typos, code, emojis. A vocabulary of whole words would be massive and would never cover everything.
Tokens are a compromise. Big enough to capture meaning, small enough to cover any text.
How it works: BPE
The algorithm behind tokenization in almost all modern LLMs is called BPE (Byte Pair Encoding). It was invented in 1994 by Philip Gage for data compression, then adapted for LLMs.
The principle is simple.
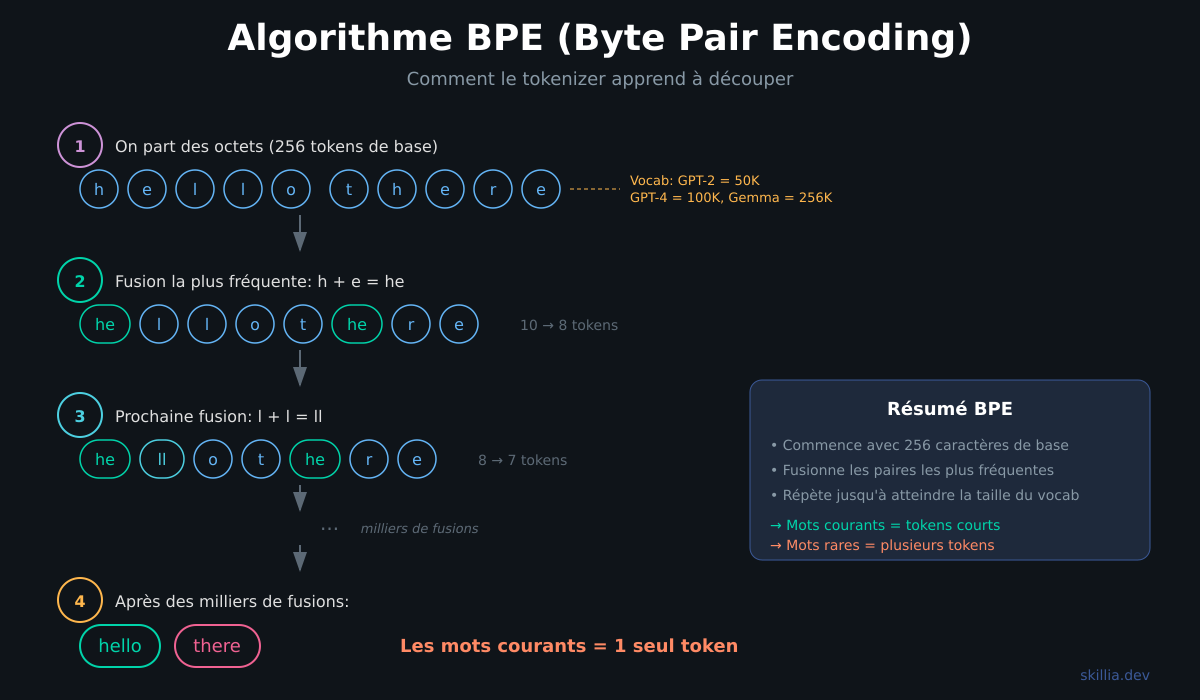
Start with individual characters. The base vocabulary contains 256 tokens, one for each possible byte.
Count the pairs. Scan all the training text and find which pairs of tokens appear most frequently. For example, "t" followed by "h" shows up all the time in English.
Merge the most frequent pair. "t" + "h" becomes a new token "th". Add it to the vocabulary.
Repeat. "th" + "e" → "the". "in" + "g" → "ing". And so on, thousands of times, until the desired vocabulary size is reached.
That's why common words often become a single token ("the", "and", "Hello") while rare words are split into multiple pieces.
Sebastian Raschka implemented BPE from scratch in a very clear notebook if you want to see the code.
Every model has its own tokenizer
An important detail: the same text doesn't produce the same tokens depending on the model.
GPT-2 had a vocabulary of 50,257 tokens. GPT-4 went to 100,258. Google's Gemma models use 256,000 tokens.
The larger the vocabulary, the more common words are represented as a single token. But it increases the model size.
In practice, if you count tokens with OpenAI's tokenizer (tiktoken), the result will differ from Anthropic's. When estimating your costs, always use the tokenizer of the model you're using.
The language problem
This is where it gets interesting for non-English speakers.
LLMs are primarily trained on English text. BPE learns its merges from this data. Result: common English words are often a single token, while French, Arabic, or Japanese words are split into more pieces.

"Hello" → 1 token. "Bonjour" → 1 token (common enough to be merged). "こんにちは" (konnichiwa) → 3-4 tokens.
A study showed that some languages require 2 to 10 times more tokens than English to express the same thing.
What does this mean in practice? You pay more for the same task in Japanese than in English. The context window fills up faster. Quality can degrade faster on long conversations.
In French, the gap is moderate (it shares many Latin roots with English), but it exists. A French text consumes on average 10 to 20% more tokens than its English equivalent.
Why tokens explain LLM quirks
Karpathy lists the problems directly caused by tokenization:
Arithmetic. The number "380" might be a single token, or "3", "80", or "38", "0". The model doesn't see digits -- it sees arbitrary chunks. It's like being asked to compute 380 + 127 but shown "thr" + "ee hundred eigh" + "ty" + " plus " + "one hun" + "dred twenty-seven". Not easy.
Spelling backwards. You ask "spell TOKYO backwards" and the LLM struggles. Because "TOKYO" is probably a single token. It doesn't see the individual letters T-O-K-Y-O.
Non-Latin languages. The more text is fragmented into small tokens, the harder it is for the model to capture meaning. This is one factor explaining why LLMs are better in English.
Python code. Python indentation (leading spaces) was poorly tokenized in GPT-2. Result: the model was bad at Python. GPT-3.5+ fixed this by adjusting the tokenizer.
In practice: understanding your bill
You pay for two things when using an LLM via API: input tokens (your prompt, the context) and output tokens (the model's response). Output is systematically more expensive, often 5x more.
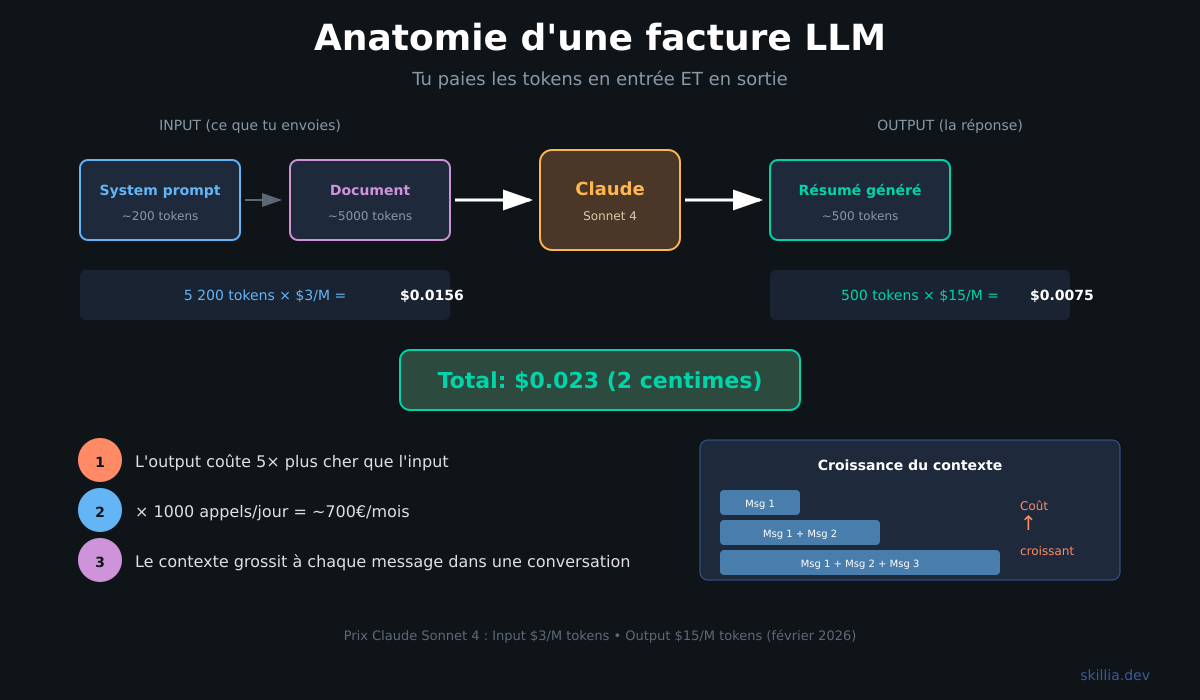
Let's take a concrete example. You want Claude to summarize a 10-page document.
Document sent: about 5,000 tokens (input). System prompt: about 200 tokens (input). Summary generated: about 500 tokens (output).
With Claude Sonnet 4.5 ($3 input / $15 output per million tokens): input costs $0.0156, output costs $0.0075. Total: about 2 cents.
Sounds like nothing. But if your agent makes 1,000 calls per day, that's $23/day, or about $700/month.
And watch out for the trap: in a conversation, every previous message is resent to the model. The context grows with each exchange. By message 20, you're potentially sending 10,000 tokens of context on every call.
In practice: counting and optimizing
Counting tokens in TypeScript
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic();
const count = await client.messages.countTokens({
model: "claude-sonnet-4-5-20250929",
messages: [{ role: "user", content: "Your message here" }]
});
console.log(`${count.input_tokens} tokens`);
Quick rule if you don't want to call the API: divide the character count by 4. It's not precise but gives you a ballpark.
Reducing costs
Prompt caching. If you send the same system prompt on every call, Anthropic caches it. You pay 10% of the price from the second call on.
const response = await anthropic.messages.create({
model: "claude-sonnet-4-5-20250929",
max_tokens: 1024,
system: [{
type: "text",
text: longSystemPrompt,
cache_control: { type: "ephemeral" }
}],
messages
});
Summarize the context. Instead of keeping all messages in a conversation, summarize the old ones and keep only the last 10.
const summary = await summarize(conversation.slice(0, -10));
const messages = [
{ role: "system", content: `Summary: ${summary}` },
...conversation.slice(-10)
];
Choose the right model. Haiku for simple tasks (classification, extraction). Sonnet for everyday use. Opus when you truly need the best reasoning. A Haiku call costs 5x less than a Sonnet call for the same token count.
Limit the output. If you need a short response, tell the model with max_tokens.
The pitfalls
Context that blows up. In an agent making calls in a loop, context can grow without you realizing. Set up a truncation or summarization mechanism.
Spaces matter. " red" (with a leading space) and "Red" (start of sentence) are different tokens. That's why your prompt formatting has an impact.
Special tokens. Models use invisible special tokens to mark the start/end of conversation, roles (user, assistant), etc. You don't see them but you pay for them.
The "SolidGoldMagikarp" bug. In 2023, researchers discovered that certain tokens in GPT's vocabulary almost never appeared in training data. When the model encountered these "ghost" tokens, it completely broke down. A reminder that tokenization isn't perfect.
In summary
Tokens are how an LLM sees text: not as words, but as chunks learned statistically by the BPE algorithm. It's what you pay for, it's what limits the model's memory, and it's the source of many unexpected behaviors.
Understanding tokens means understanding why your bill is what it is, why French costs a bit more than English, and why your LLM struggles with math.
To see how tokens fit into the full workings of an LLM, check out our guide What is an LLM.
Sources: