What is an LLM?
Large Language Models explained simply. What they are, how they work, and what they can do.
Someone starts a sentence: "Once upon a..."
You immediately think "time".
Or: "The capital of France is..."
You think "Paris".
This reflex of predicting what comes next is exactly what an LLM does. Except it does it after reading a huge chunk of the internet.
What is an LLM?
A Large Language Model (LLM) is a program trained on a massive amount of text (books, articles, code, forums) that predicts the next word in a sequence.
You type "The cat sleeps on the..." and the model calculates probabilities: "couch" 23%, "roof" 18%, "bed" 12%... It picks a word, adds it to the sequence, and starts over. Word by word, it builds complete responses.
Everything an LLM does -- summarizing a document, writing code, answering a question -- is text prediction. The quality comes from the volume of data it was trained on and the architecture that enables it to understand context.

How it works
What makes modern LLMs powerful is the Transformer architecture (the "T" in GPT).
Unlike older approaches that processed text word by word, Transformers analyze the entire context in parallel.
The key mechanism is called attention: for each word, the model evaluates which other words are important to understand it.
Example with "The cat that was sleeping on the couch woke up": to understand "woke up", the model needs to know that "the cat" is performing the action. Attention makes this connection possible, even when words are far apart in the sentence.

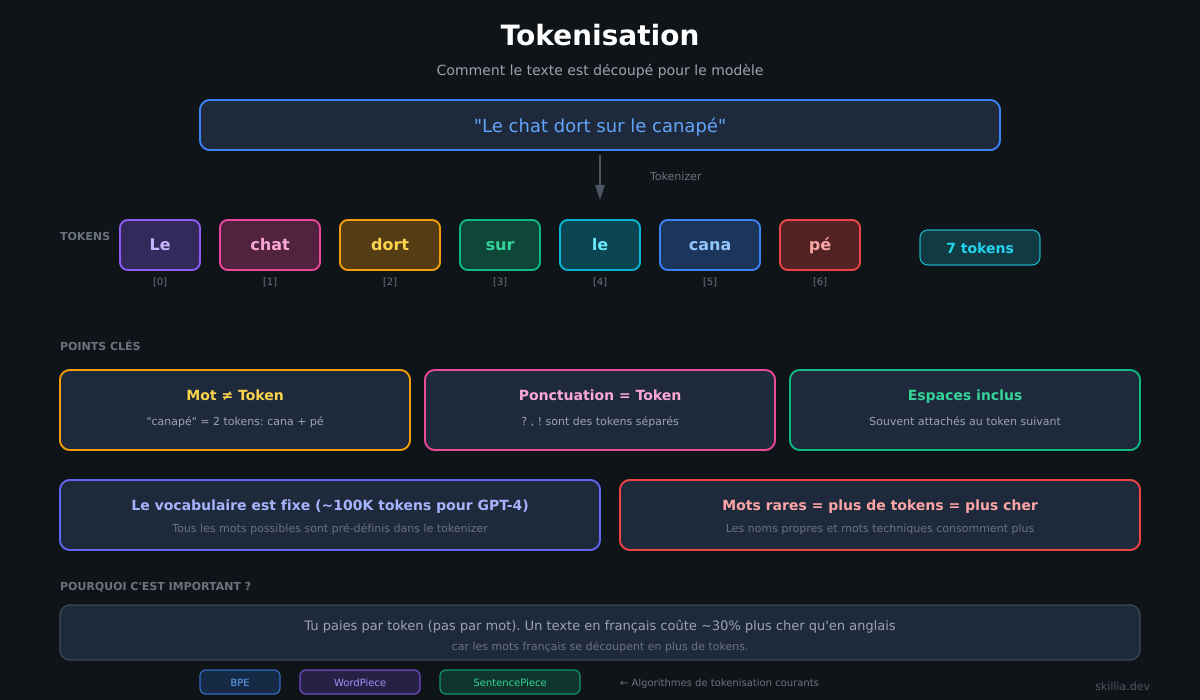
Text is split into small units called tokens. A token can be a whole word, part of a word, or even a punctuation mark. The model works with these tokens, not with words in the traditional sense.
The full pipeline
Between your question and the model's response, there are 6 transformations.
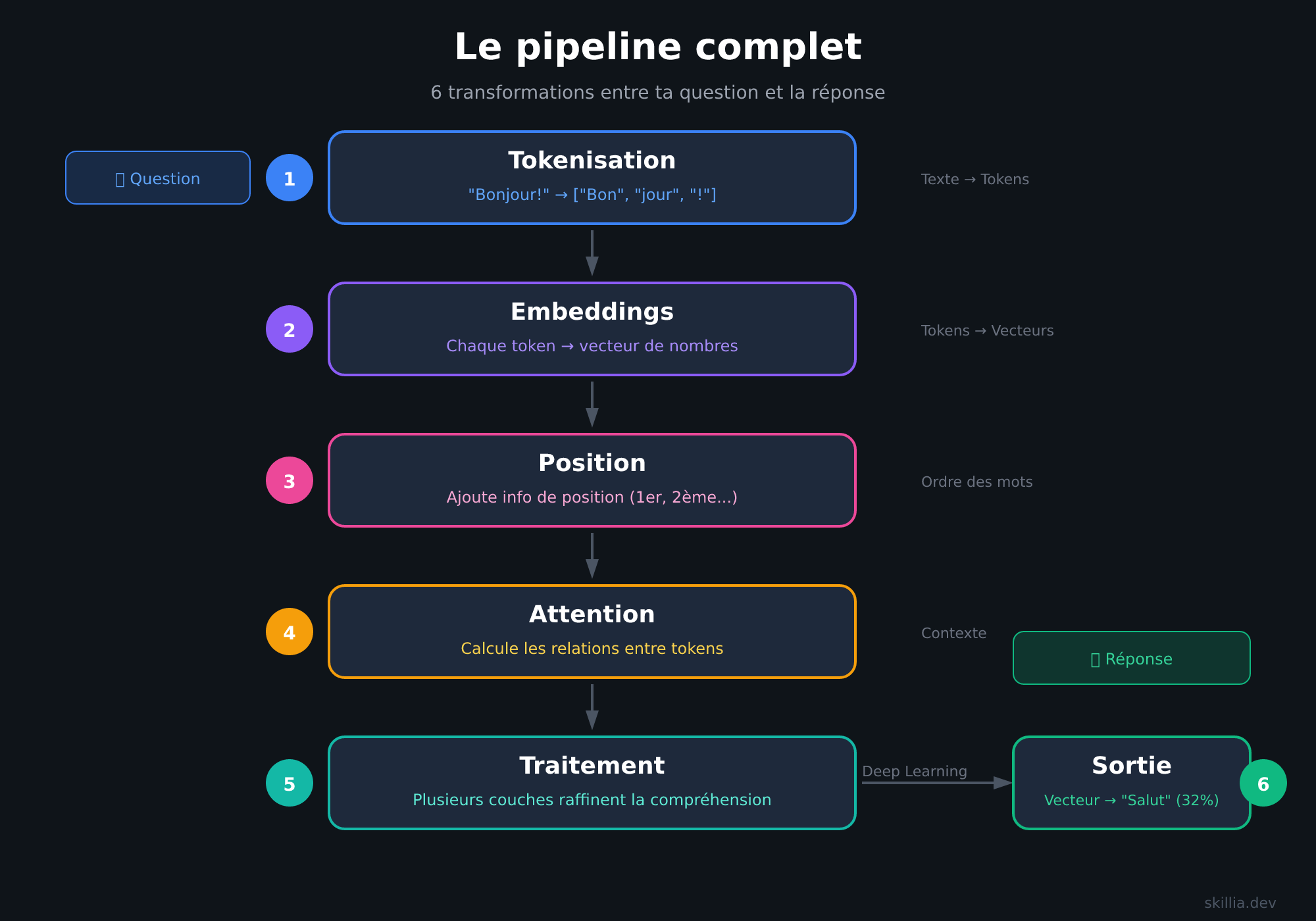
"Hello!"
↓
[1. Tokenization] → ["Hel", "lo", "!"]
↓
[2. Embeddings] → Each token becomes a vector of numbers
↓
[3. Position] → The model knows "Hel" is at position 1
↓
[4. Attention] → The model calculates relationships between tokens
↓
[5. Processing] → Multiple layers refine the understanding
↓
[6. Output] → The final vector becomes probabilities → "Hi" (32%), "Hey" (18%)...
Tokenization: Text is split into tokens (words or word fragments).
Embeddings: Each token becomes a vector -- a list of 768 to 4,096 numbers. Similar words have similar vectors. This is what allows the model to understand that "cat" and "dog" are related.
Position: The model adds position information. Without it, "The cat eats the mouse" and "The mouse eats the cat" would be identical.
Attention: For each token, the model calculates which other tokens matter. This is the heart of the Transformer -- what allows it to understand context.
Processing: The signal passes through dozens of layers. The first ones capture grammar, the middle ones capture meaning, the last ones handle abstract reasoning.
Output: The final vector is compared to all possible tokens. This produces a probability for each word. The model samples from these probabilities to generate the response.
This cycle repeats for every generated token. That's why longer responses take more time and cost more.
Generation parameters
When the model reaches step 6 (output), it has a list of probabilities for each possible word. But how does it choose?
That's where generation parameters come in. You'll find them in every API (OpenAI, Anthropic, etc.).
Temperature -- The creativity slider.

- 0: The model always picks the most probable word. Identical responses every time.
- 0.3: Slight variation. Ideal for factual tasks (code, analysis).
- 0.7: Balanced. The default for most APIs.
- 1.0+: More creativity, but risk of incoherence.
Top-p (nucleus sampling) -- Limits choices to the most probable words.
With top_p=0.9, the model only considers words that represent 90% of the total probability. Unlikely words are excluded.
Top-k -- Even stricter.
With top_k=50, the model only chooses from the 50 most probable words, regardless of their combined probability.
In practice:
- Code, analysis, factual →
temperature: 0.2-0.5 - Conversation, writing →
temperature: 0.7(default) - Creative, brainstorming →
temperature: 0.9-1.0
Most of the time, you only need to adjust temperature. Top-p and top-k are there for advanced use cases.
How an LLM is built
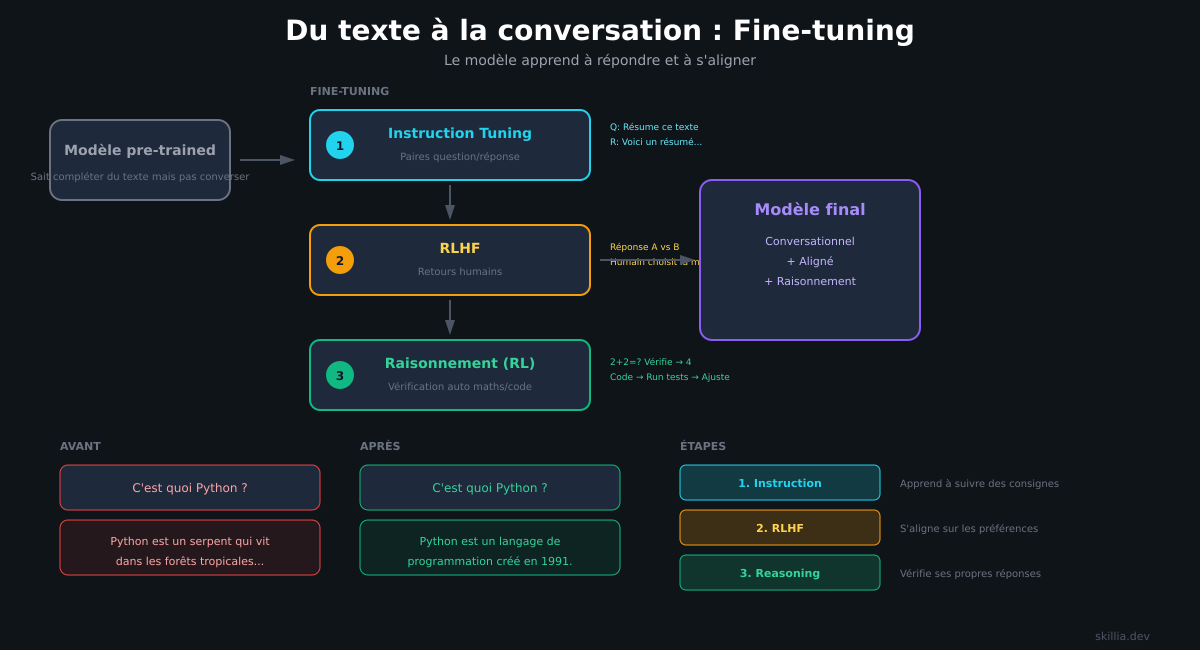
An LLM isn't born smart. It becomes smart in 4 stages.
Stage 1: The raw model. At the start, the model knows nothing. You ask "What is an LLM?" and it responds with gibberish. Its parameters (the internal values it adjusts to learn) are random.
Stage 2: Pre-training. It reads billions of pages of text. It learns grammar, facts about the world, code patterns. After this stage, it can complete text. But it can't hold a conversation. If you ask it a question, it'll just continue your sentence instead of answering.
Stage 3: Instruction fine-tuning. It's trained on question/answer pairs to learn to follow instructions. This is the stage where it becomes conversational. It can now answer questions, summarize content, write code.
Stage 4: Preference and reasoning fine-tuning. Human feedback is used to refine its responses. You know when ChatGPT asks "Which response do you prefer?" That's not just for feedback -- it's training data. The model learns to align with what humans expect. For reasoning tasks (math, logic), automated verification is used: the model generates an answer, it's compared to the correct one, and the model adjusts.
These 4 stages transform a random program into a tool capable of writing, analyzing, and reasoning.

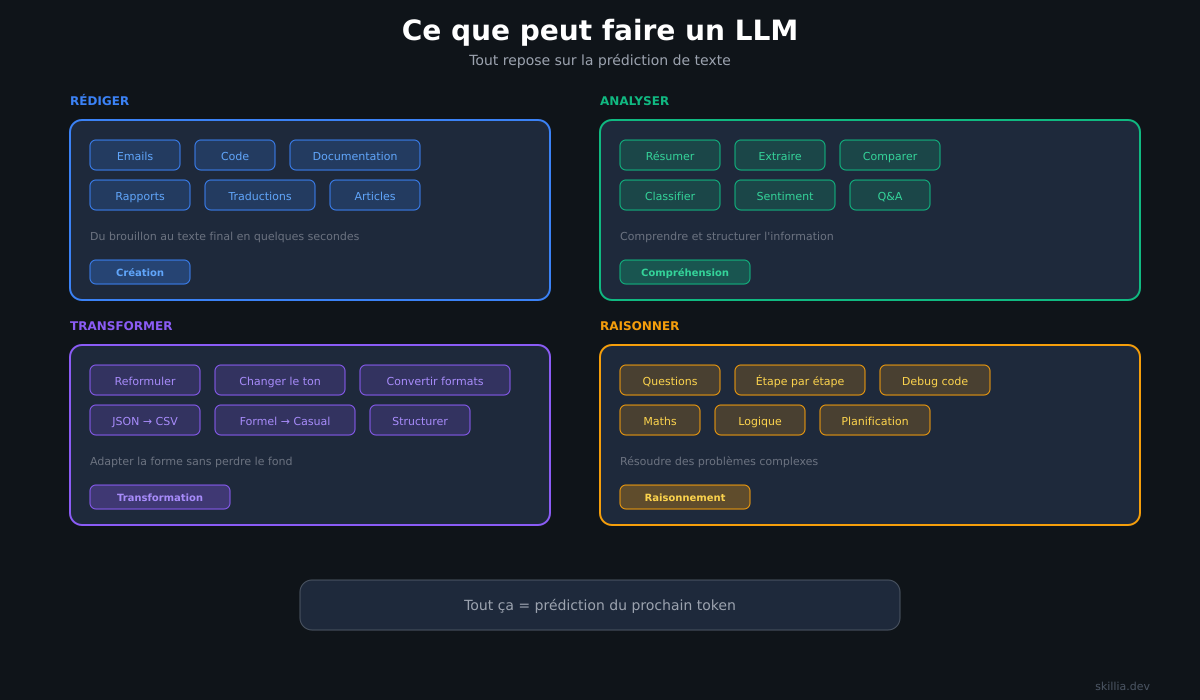
What it can do
An LLM generates text. Sounds simple, but it covers a lot.
Write:
- Emails, reports, documentation
- Code in any language
- Translations
Analyze:
- Summarize a document
- Extract key information
- Compare texts
Transform:
- Rephrase text
- Change tone or style
- Convert one format to another (JSON → CSV, etc.)
Reason:
- Answer complex questions
- Solve problems step by step
- Debug code
The limitations
LLMs aren't perfect.
Hallucinations. The model can make up information with total confidence. It generates what's probable, not what's true. Always verify important facts.
No memory. Every conversation starts from scratch. The model doesn't remember what you told it yesterday (unless you use techniques like CLAUDE.md to give it context).
Limited context window. The model can only process a limited amount of text at a time. The longer the conversation, the more quality can degrade.
Costs. The most powerful models are expensive. You pay for what you send (your question, your context) and for what the model generates (its response). Example: Claude Opus 4.5 costs $5 per million input tokens and $25 per million output tokens. At scale, it adds up fast.

What has changed
LLMs from two years ago had frustrating limitations. The 2026 models are significantly more reliable.
The main change: reasoning models.
Instead of answering directly, newer models "think" step by step before giving a response. Result: fewer errors on complex tasks.
Claude Opus 4.5 solves 80.9% of real code bugs on SWE-bench. GPT-5.2 reaches 92.4% on GPQA (a scientific reasoning benchmark). Gemini 3 Pro hits 91.9% on GPQA with a 1 million token context window.
Hallucinations are less frequent, reasoning is more solid.

Which model to choose?
Paid models (via API):
- Claude Opus 4.5 ($5/$25, 200K context): #1 on Arena ranking (1554). SWE-bench 80.9%, GPQA 87.0%. Top performer on complex tasks and coding.
- Gemini 3 Pro ($2/$12, 1M context): #2 Arena (1519). GPQA 91.9%. Massive 1 million token context window for analyzing entire documents.
- GPT-5.2 ($1.75/$14, 400K context): #3 Arena (1432). GPQA 92.4%, SWE-bench 80.0%. Best price-to-performance ratio among closed models. Its Codex variant is optimized for code.
- Gemini 3 Flash ($0.50/$3, 1M context): #4 Arena (1357). GPQA 90.4%, SWE-bench 78.0%. Best price-to-performance ratio across the board. Ideal for high volume.
- Claude Sonnet 4.5 ($3/$15, 200K context): Coding Arena 1203 (#1 in code). GPQA 83.4%. Good enough for 80% of use cases.
Open source models:
- Kimi K2.5 (Moonshot): $0.60/$2.50, 262K context. GPQA 87.6%, SWE-bench 76.8%. Open source and highly competitive for the price.
- GLM-4.7 (Zhipu AI): $0.60/$2.20, 205K context. Coding Arena 1029, GPQA 85.7%. A Chinese outsider to watch.
- GLM-4.6 (Zhipu AI): $0.55/$2.19, 131K context. SWE-bench 68.0%. Even more affordable.
- Llama 4 (Meta): Context up to 10M tokens with Scout. Permissive license but branding required.
- DeepSeek R1: MIT license, zero restrictions. Strong at reasoning.
In practice: Start with Claude Sonnet 4.5 or GPT-5.2 to test. Switch to Kimi K2.5 or GLM when you need to scale or cut costs.
Data: llm-stats.com -- January 2026
Where to start?
-
Experiment. Ask questions, test the limits. It's the best way to understand what the model can and can't do.
-
Be specific. The quality of your results depends on the quality of your instructions. Give context, explain what you expect.
-
Verify. Never trust blindly. LLMs are tools, not oracles.
-
Iterate. If the result isn't good, rephrase. Prompting is a conversation, not a one-shot command.
In summary
An LLM is a program that predicts the next word after reading billions of pages of text. It's built in 4 stages: pre-training, instruction tuning, human preferences, and reasoning.
In 2026, with reasoning models, it's become a reliable tool for writing, analyzing, transforming, and reasoning about text.
It's not magic, it's not perfect, but it's powerful enough to change the way you work.
Sources: