La context window : la mémoire de travail d'un LLM
La context window, c'est la quantité de texte qu'un LLM peut traiter en une seule fois. Comprends ses limites réelles, le context rot, et comment optimiser ton usage.
Tu colles un document de 200 pages dans Claude. Le résumé des 50 premières pages est impeccable. Mais à la fin, le modèle commence à inventer des trucs qui ne sont pas dans le document.
C'est la context window. La quantité de texte qu'un LLM peut "voir" en une seule fois. Tout ce que tu lui envoies (ta question, le document, l'historique de conversation, sa propre réponse en cours) doit rentrer dedans.
Au-delà de cette limite, le modèle ne tronque pas. Il perd en qualité. Et la différence entre un bon et un mauvais usage d'un LLM se joue souvent là.
L'intuition
Imagine que tu travailles sur un bureau. Tu peux étaler un certain nombre de documents devant toi. C'est ta mémoire de travail.
Un LLM, c'est pareil. Sa context window, c'est son bureau. Tout ce qui rentre sur le bureau, il peut le voir et l'utiliser. Ce qui ne rentre pas, il ne le connaît pas.
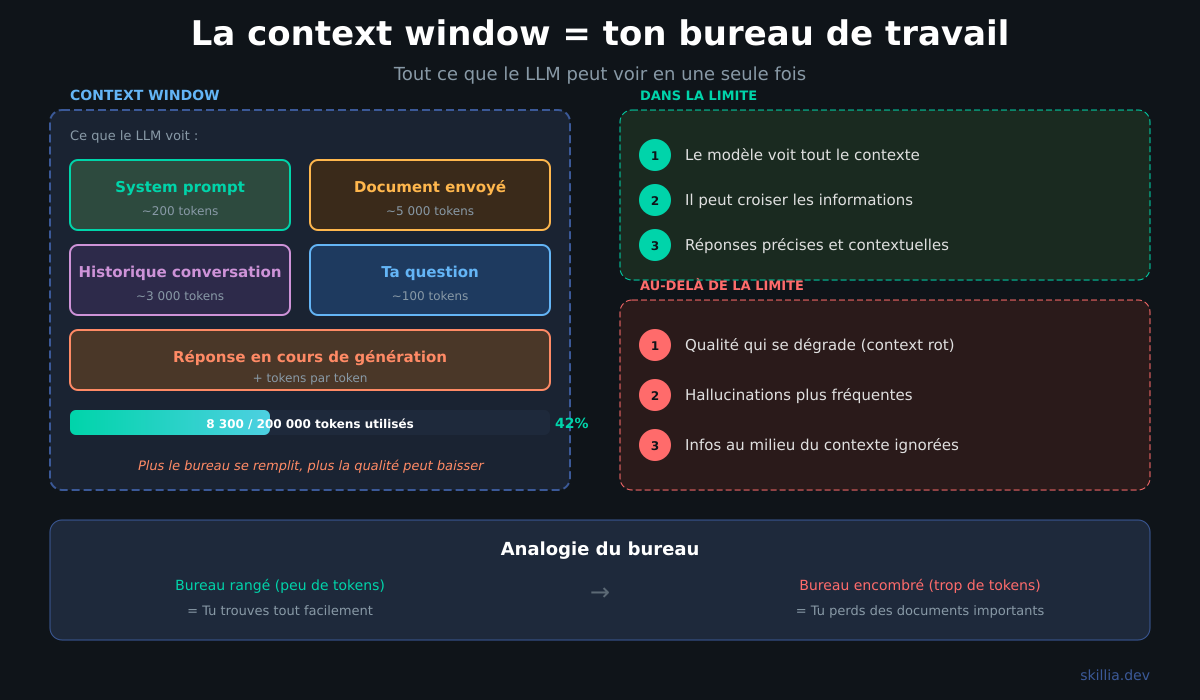
La différence avec un humain? Toi, tu peux te lever et aller chercher un document dans un tiroir. Un LLM ne peut pas. Il n'a que son bureau. Et même sur un très grand bureau, les documents au fond deviennent difficiles à lire.
La context window se mesure en tokens (les unités de texte que le modèle traite). En règle générale, 1 token ≈ 4 caractères en anglais, un peu moins en français. 100K tokens ≈ 250 pages de texte.
Les tailles en 2026
Les context windows ont explosé ces deux dernières années. Epoch AI a mesuré que les plus grandes fenêtres de contexte croissent d'environ 30x par an depuis mi-2023.
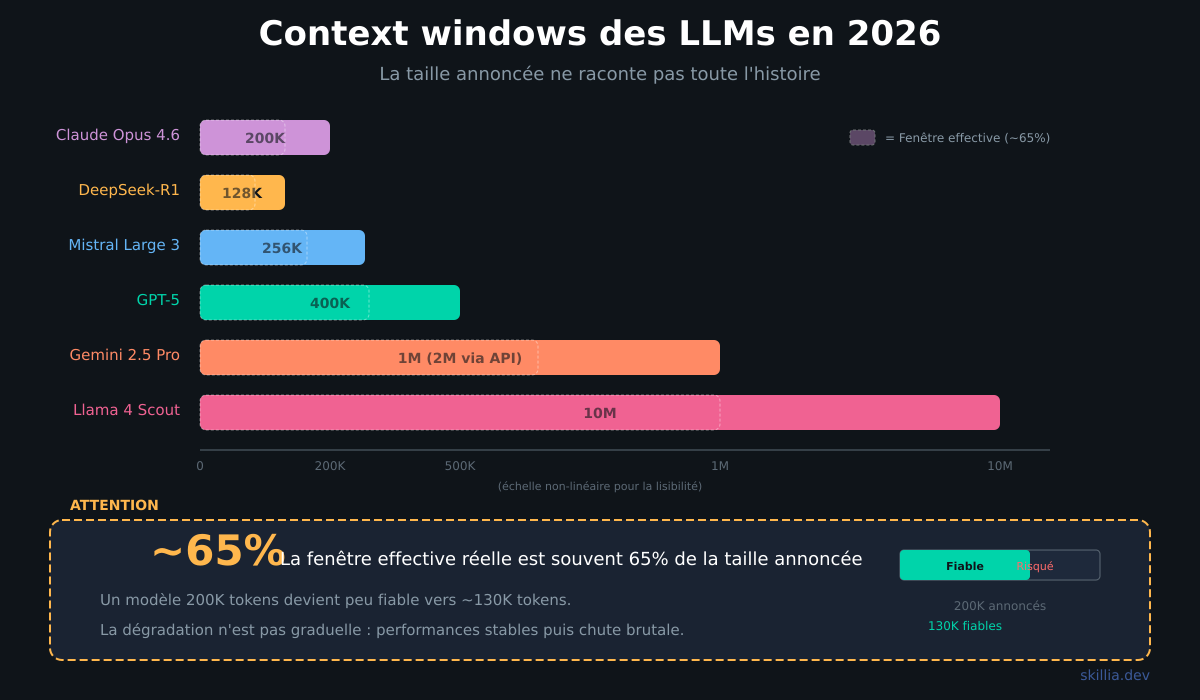
| Modèle | Context Window | Équivalent | |--------|---------------|------------| | Claude Opus 4.6 | 200K tokens | ~500 pages | | GPT-5 | 400K tokens | ~1 000 pages | | Gemini 2.5 Pro | 1M tokens (2M via API) | ~2 500 pages | | Llama 4 Scout | 10M tokens | ~25 000 pages | | DeepSeek-R1 | 128K tokens | ~320 pages | | Mistral Large 3 | 256K tokens | ~640 pages |
Mais un bureau plus grand ne veut pas dire un meilleur travail. Et c'est là que ça devient intéressant.
Le vrai problème : le context rot
Simon Willison a nommé le phénomène context rot : la qualité des réponses d'un modèle se dégrade à mesure que le contexte s'allonge, même quand on reste dans la limite annoncée.
Un modèle qui annonce 200K tokens ne maintient pas la même qualité sur toute cette plage. Les chercheurs de Chroma Research l'ont mesuré rigoureusement : 18 modèles testés, 194 480 appels LLM, 8 longueurs d'input, 11 positions de needle.
Leurs constats sont frappants :
- Les performances varient significativement même sur des tâches simples quand l'input s'allonge
- Les modèles performent mieux sur des textes mélangés aléatoirement que sur des documents structurés cohérents (l'attention serait "distraite" par le flux narratif)
- Claude montre les plus faibles taux d'hallucination, avec une tendance à s'abstenir en cas d'incertitude
- GPT montre les plus hauts taux d'hallucination, avec des réponses incorrectes mais confiantes

Une étude académique va encore plus loin : la "Maximum Effective Context Window" (la taille réelle utilisable) tombe parfois à 1% de la taille annoncée. Certains modèles top de gamme échouent avec seulement 100 tokens de contexte sur certaines tâches.
Le benchmark classique "Needle in a Haystack" (cacher une info dans un long texte et demander au modèle de la retrouver) masque le problème. Il teste juste la correspondance lexicale directe. Les vrais cas d'usage sont plus complexes : synthétiser, raisonner sur plusieurs passages, croiser des informations dispersées.
Pourquoi ça arrive : le coût quadratique de l'attention
Pour comprendre le context rot, il faut revenir au mécanisme d'attention au cœur des Transformers.
L'attention standard fonctionne comme ça : chaque token doit "regarder" tous les autres tokens pour comprendre le contexte. Avec 1 000 tokens, ça fait 1 000 × 1 000 = 1 million de calculs. Avec 100 000 tokens, ça fait 100 000 × 100 000 = 10 milliards de calculs.
C'est une complexité quadratique (O(n²)). Doubler le contexte = 4x le calcul et 4x la mémoire. C'est LE goulot d'étranglement fondamental.
En pratique, ça se traduit par un composant appelé KV cache (Key-Value cache). Le modèle stocke les clés et valeurs déjà calculées pour ne pas tout recalculer à chaque nouveau token généré. Le problème : ce cache grossit linéairement avec le contexte. Pour un modèle comme Llama 3 70B à 128K tokens, le KV cache pèse environ 40 Go de mémoire pour un seul utilisateur.
C'est pour ça que les providers facturent plus cher les longs contextes. Claude Sonnet 4.5 passe de $3/M tokens à $6/M tokens au-dessus de 200K.
Comment les modèles s'adaptent
Les labos ne sont pas restés les bras croisés. Sebastian Raschka note que les LLMs open-weight convergent en 2025 vers au moins un mécanisme d'attention optimisé.
Grouped-Query Attention (GQA) est devenu le standard (Llama 3, GPT-4). Au lieu de calculer des clés et valeurs uniques pour chaque tête d'attention, GQA partage les têtes K/V entre plusieurs têtes de requête. Résultat : le KV cache est réduit proportionnellement.
Sliding Window Attention (SWA) limite chaque token à ne regarder que les w tokens précédents (une fenêtre fixe). La complexité passe de O(n²) à O(w × n), linéaire en n. Le gain mesuré : un speedup de 3.6x sur des contextes de 128K tokens. Le compromis : perte d'information globale, compensée par des couches d'attention complète intercalées.
Multi-Head Latent Attention (MLA), l'innovation de DeepSeek, compresse les tenseurs K/V dans un espace latent de dimension réduite avant de les stocker. À l'inférence, ils sont décompressés pour retrouver des K/V uniques par tête. TransMLA compresse 93% du KV cache et atteint un speedup de 10.6x à 8K tokens de contexte.
Et pour passer de 512 tokens (le Transformer original de 2017) à des millions, il a fallu repenser l'encodage des positions. RoPE (Rotary Position Embedding) et ses extensions (YaRN, iRoPE) permettent au modèle de généraliser à des longueurs jamais vues à l'entraînement. C'est la technologie clé derrière les 10M tokens de Llama 4 Scout.
En pratique : optimiser ton usage
Compter les tokens
Avant d'optimiser, il faut mesurer. Voici comment compter les tokens avec le SDK Anthropic :
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic();
const count = await client.messages.countTokens({
model: "claude-sonnet-4-5-20250929",
messages: [{ role: "user", content: "Ton message ici" }]
});
console.log(`${count.input_tokens} tokens`);
Règle rapide sans API : divise le nombre de caractères par 4.
Prompt caching
Si tu envoies le même system prompt à chaque appel (et c'est souvent le cas), le prompt caching change tout. Anthropic met en cache les tenseurs KV déjà calculés. Tu paies 10% du prix à partir du deuxième appel, avec une réduction de latence de 85%.
const response = await anthropic.messages.create({
model: "claude-sonnet-4-5-20250929",
max_tokens: 1024,
system: [{
type: "text",
text: longSystemPrompt,
cache_control: { type: "ephemeral" }
}],
messages
});
Sur un agent qui fait 1 000 appels par jour avec un system prompt de 2 000 tokens, ça peut réduire la facture de plusieurs centaines d'euros par mois.
RAG vs long context
Tu as un gros corpus de documents. Tu les colles tous dans le contexte, ou tu utilises du RAG (Retrieval-Augmented Generation) pour ne chercher que les passages pertinents?
Une étude compare les deux approches. Le verdict : il n'y a pas de solution universelle, mais les chiffres parlent.
- Coût : RAG = ~$0.00008 par requête vs Long Context = ~$0.10 par requête. RAG est 1 250x moins cher.
- Vitesse : RAG = ~1 seconde vs Long Context = ~45 secondes.
- Qualité : Long Context gagne sur les tâches de question-answering sur des documents continus. RAG gagne sur les dialogues et les requêtes générales.
En pratique, les meilleurs systèmes combinent les deux. RAG pour le gros du travail (chercher les bons passages), long context pour affiner la réponse avec suffisamment de contexte autour.
Résumer le contexte
Dans une conversation longue, chaque message précédent est renvoyé au modèle. Au message 20, tu envoies potentiellement 10 000 tokens de contexte à chaque appel.
La stratégie : résumer les anciens messages et garder seulement les 10 derniers.
const summary = await summarize(conversation.slice(0, -10));
const messages = [
{ role: "user", content: `Contexte précédent: ${summary}` },
...conversation.slice(-10)
];
C'est exactement ce que fait Claude Code quand ta conversation devient trop longue : il "compacte" le contexte en résumant les phases précédentes.
Les pièges
Fenêtre annoncée ≠ fenêtre effective. Un modèle qui annonce 200K tokens devient généralement peu fiable autour de 130K tokens (65% de l'annonce). La dégradation n'est pas graduelle : le modèle maintient de bonnes performances puis chute brutalement à un seuil.
Le context poisoning. Drew Breunig identifie 4 types de "context rot" :
- Context Poisoning : des erreurs entrent dans le contexte et le modèle les réfère en boucle
- Context Distraction : un long contexte fait que le modèle se concentre trop dessus et néglige son entraînement
- Context Confusion : des infos superflues mènent à des réponses de mauvaise qualité
- Context Clash : de nouvelles infos entrent en conflit avec le contexte existant
Le coût invisible. Plus ton contexte est long, plus chaque appel coûte cher. Dans un agent qui fait des appels en boucle, le contexte peut grossir sans que tu t'en rendes compte. Mets un mécanisme de troncature ou de résumé.
La position de l'info compte. Les modèles ont tendance à mieux utiliser les informations au début et à la fin du contexte. Le milieu est souvent la "zone morte". Si tu as une instruction critique, mets-la au début de ton prompt.
En résumé
La context window, c'est la mémoire de travail d'un LLM. Elle se mesure en tokens, elle a grandi de 512 à 10 millions en quelques années, mais la taille annoncée ne raconte pas toute l'histoire. Le context rot dégrade la qualité bien avant d'atteindre la limite.
En pratique : compte tes tokens, utilise le prompt caching, combine RAG et long context, et résume les conversations longues. Ton LLM travaillera mieux avec un bureau bien organisé qu'avec un bureau surchargé.
Pour voir comment la context window s'intègre dans le fonctionnement complet d'un LLM, c'est expliqué dans notre guide C'est quoi un LLM.
Sources: