RAG vs Long Context: do you still need a vector database?
Context windows now hold millions of tokens. So why not just dump everything in? Here's when RAG still wins, when long context is better, and how to choose.
LLMs are frozen in time. They know everything up until their training cutoff date and absolutely nothing about what happened 5 minutes ago. They don't know about your private data, your internal wikis, your codebase.
If you want an LLM to know any of that stuff, you have to solve the problem of context injection. How do you get the right data into the model at the right time?
There are two fundamentally different approaches. And the choice between them might be the most important architectural decision you make.
The two approaches
RAG (Retrieval Augmented Generation) is the engineering approach. You chunk your documents, pass them through an embedding model, store the vectors in a database, and when a user asks a question, you retrieve the most relevant chunks and inject them into the context window.
It works, but it relies on something fragile: the hope that your retrieval logic actually found the right information.
Long context is the brute force approach. You skip the database, skip the embedding model, and dump your documents straight into the context window. You let the model's attention mechanism do the heavy lifting of finding the answer.
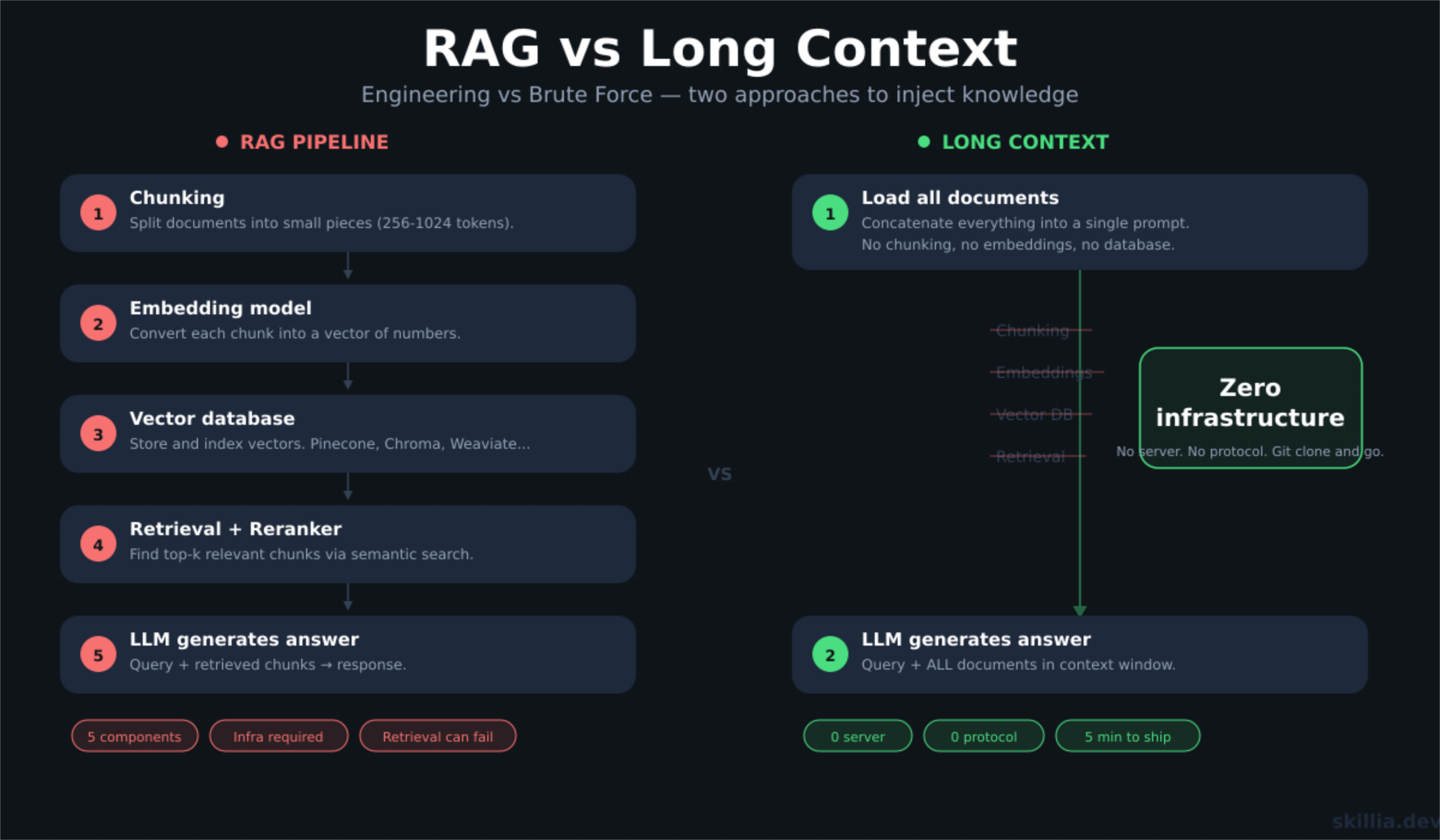
For a long time, the brute force method wasn't an option. Early LLMs had context windows of 4K tokens. You couldn't fit a novel in there, let alone a knowledge base. You basically had to use RAG.
But today's models have context windows of a million tokens or more. A million tokens is roughly 700,000 words. You could fit the entire Lord of the Rings series and still have room for The Hobbit.
This forces a difficult question: if you can Ctrl+A, Ctrl+C, Ctrl+V all your documentation into the context window, do you really need the overhead of embedding models and vector databases?
3 reasons to go Long Context
1. Collapsing the infrastructure
A production RAG system is heavy. You need:
- A chunking strategy (fixed size? sliding window? recursive? semantic?)
- An embedding model to encode the data
- A vector database to store it
- A reranker to sort the results
- A sync mechanism to keep vectors up to date with source data
That's a lot of moving parts. A lot of places for things to break.
Long context offers what we might call the "no stack stack". You remove the database, the embeddings, the retrieval logic. The architecture simplifies down to: get the data, send it to the model.
2. The retrieval lottery
RAG introduces a critical point of failure: the retrieval step itself.
When a user asks a question, RAG looks at mathematical representations of the data (vectors -- basically long arrays of numbers) and tries to find the closest match. That's semantic search. But semantic search is probabilistic.
For all sorts of reasons, the retrieval might fail to find the relevant document. This is called silent failure: the answer existed in the data, but the LLM never saw it because the retrieval step didn't return the right results.
With long context, there is no retrieval step. The model sees everything.
3. The whole book problem
RAG is designed to retrieve what exists. It relies on finding a semantic match between your query and a specific snippet of text.
But what if the answer lies in what's not in the database?
Example: you have a set of product requirements and a set of release notes. You ask: "Which security requirements were omitted from the final release?"
RAG retrieves snippets about security from the requirements doc. It retrieves snippets from the release notes. But it cannot retrieve the gap between them. Because RAG only shows the model isolated snapshots, the model never sees the full picture required to spot the missing pieces.
The model needs both documents in full to perform the comparison. That's exactly what long context does.
3 reasons RAG still wins
1. The rereading tax
Long context creates a massive compute inefficiency.
Take a 500-page manual. That's roughly 250K tokens. With long context, you process those 250K tokens every single query. The model rereads the entire manual every time someone asks a question.
RAG pays the processing cost once, at indexing time. After that, each query only processes the relevant chunks (maybe 2-5K tokens).
Prompt caching can partially offset this for static data. But for dynamic data that changes frequently, you're stuck paying the full tax on every request.
The cost difference is significant. Research shows RAG queries cost around $0.00008 each, while long context queries cost around $0.10 each. That's 1,250x cheaper for RAG.
2. Needle in the haystack
There's an intuitive assumption that if data is in the context window, the model will use it. Research suggests otherwise.
As the context window grows, the model's attention mechanism gets diluted. If you ask a specific question about a single paragraph buried in the middle of a 2,000-page document, the model often fails to retrieve it. Or worse, it hallucinates details from surrounding text.
RAG removes the haystack and presents the model with just the needles. By retrieving only the top 5 relevant chunks, it forces the model to focus on the signal, not the noise.
3. The infinite dataset
A context window of millions of tokens sounds impressive. In the context of enterprise data, it's a drop in the bucket.
An enterprise data lake is measured in terabytes or petabytes. No context window will ever hold all of that. If you need access to an unbounded dataset, you need a retrieval layer to filter information down to something that fits.
How to choose
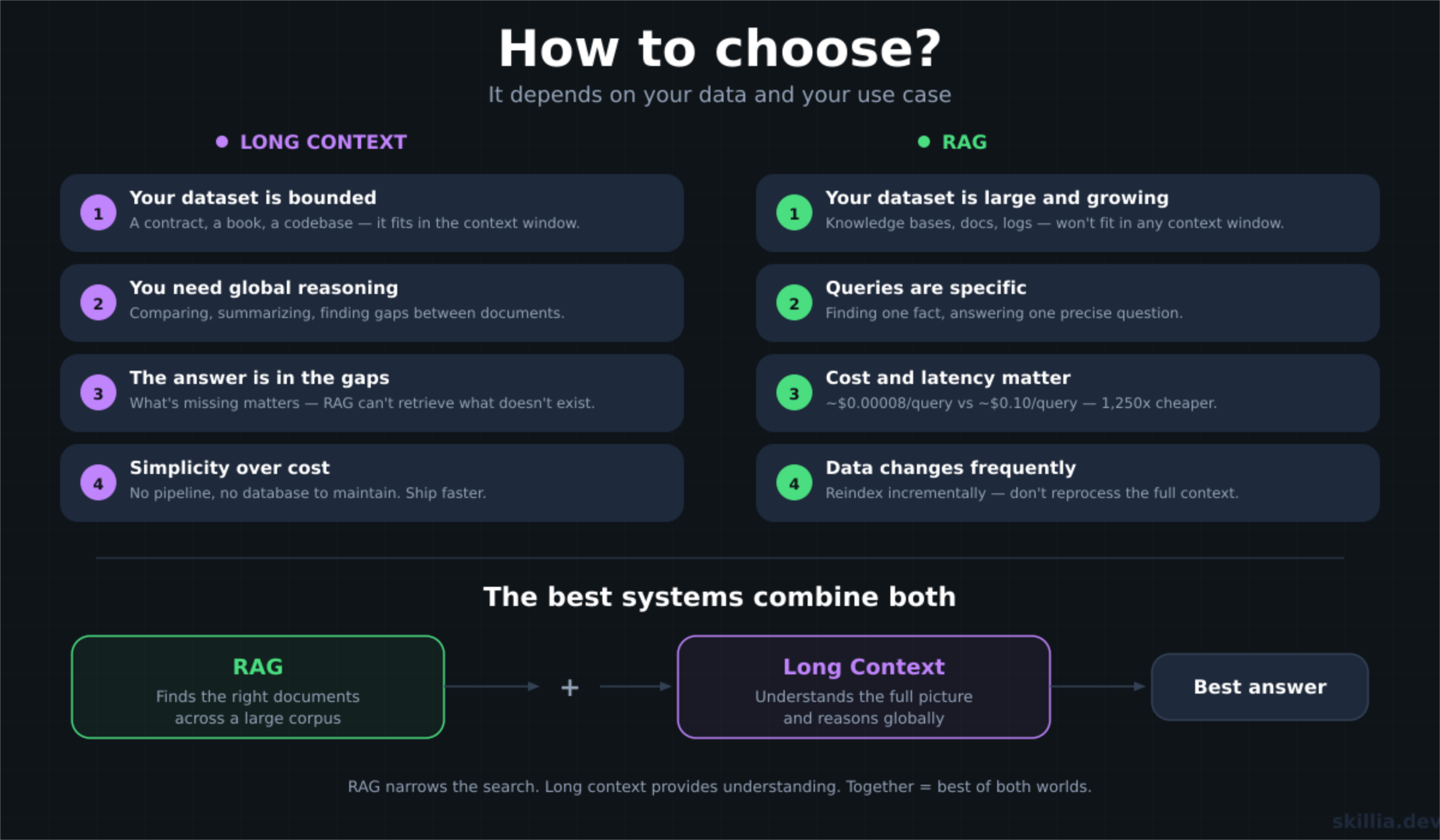
The decision isn't binary. It depends on your data and your use case.
Go with long context when:
- Your dataset is bounded (a specific contract, a book, a codebase)
- The task requires global reasoning (comparing documents, finding gaps, summarizing)
- You need to see the full picture, not just isolated snippets
- Simplicity matters more than cost optimization
Go with RAG when:
- Your dataset is large and growing (knowledge bases, documentation, logs)
- Queries are specific (finding a particular fact, answering a precise question)
- Cost and latency matter (high-volume production systems)
- Data changes frequently and reindexing is cheaper than reprocessing
The best systems combine both. Use RAG for the heavy lifting (searching across a large corpus to find the right documents), then use long context to give the model enough surrounding context to reason properly. RAG finds the right documents. Long context lets the model actually understand them.
The bottom line
RAG isn't dead. Long context isn't a silver bullet.
RAG is an engineering solution to a scale problem. Long context is a model-native solution to a reasoning problem. They solve different things.
The real question isn't "RAG or long context?" It's "what does my data look like, and what kind of reasoning does my task require?"
Answer that, and the architecture follows.
Sources: