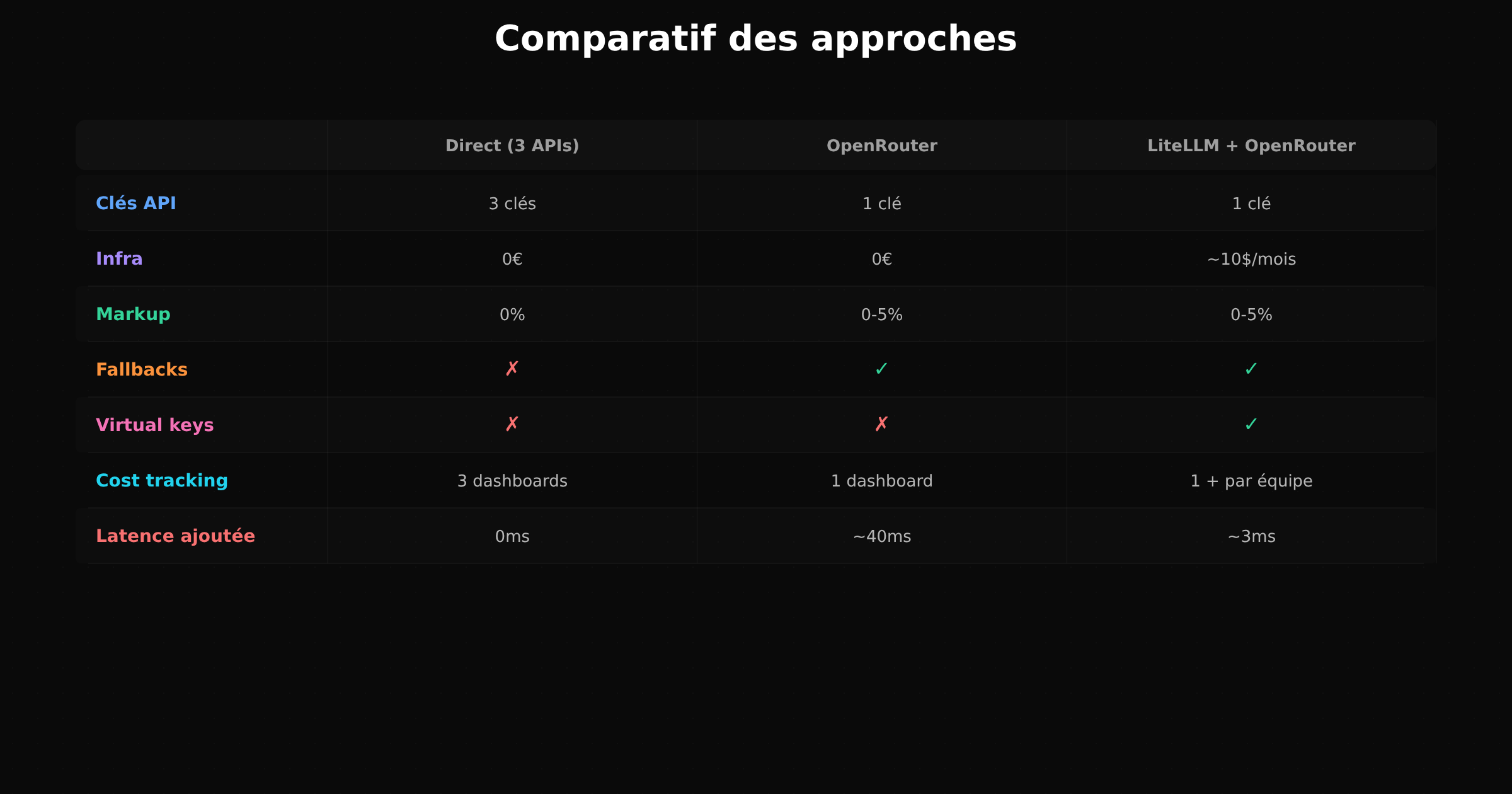
Virtual keys, coûts et pièges
Au-delà du routing, LiteLLM apporte des fonctionnalités que tu n'as pas avec un accès direct aux APIs.
Virtual keys
Tu crées des clés API par projet ou par équipe, chacune avec un budget max. Plus de risque qu'un script fou explose ta facture.
curl https://ton-litellm/key/generate \
-H "Authorization: Bearer sk-master-key" \
-d '{"models": ["skillia.dev", "claude-sonnet"], "max_budget": 50}'
Tu peux aussi limiter les requêtes par minute et les tokens par minute :
curl https://ton-litellm/key/generate \
-H "Authorization: Bearer sk-master-key" \
-d '{
"models": ["skillia.dev"],
"max_budget": 50,
"tpm_limit": 1000,
"rpm_limit": 100
}'
Fallbacks automatiques
Claude est down ? LiteLLM bascule sur GPT automatiquement. Tes apps ne plantent jamais.
litellm_settings:
fallbacks: [{"claude-sonnet": ["gpt-4o"]}]
allowed_fails: 3
cooldown_time: 30
Tu peux aussi configurer un fallback universel :
litellm_settings:
default_fallbacks: ["gpt-4o"]
Cost tracking
Chaque requête est tracée. Tu vois tes dépenses par modèle, par clé, par équipe dans le dashboard (/ui). Le header x-litellm-response-cost te donne le coût de chaque appel.
# Dépenses par clé
curl https://ton-litellm/key/info?key=sk-ta-cle
# Dépenses par équipe
curl https://ton-litellm/team/info?team_id=mon-equipe
# Rapport global
curl "https://ton-litellm/global/spend/report?start_date=2026-02-01&end_date=2026-02-28&group_by=team"
Les vrais coûts
| Composant | Coût | Ce que tu obtiens | |-----------|------|-------------------| | Elestio (hébergement LiteLLM) | ~10-25$/mois | Proxy, dashboard, SSL, backups | | OpenRouter (accès aux modèles) | Prix du provider + 0-5% markup | 300+ modèles, une seule API | | OpenCode | Gratuit (open-source) | Agent terminal |
Ihor Novytskyi note que la latence ajoutée par LiteLLM self-hosted est d'environ 3ms (contre ~40ms pour OpenRouter seul). Le proxy local est quasi transparent.
L'équipe de Berkeley derrière RouteLLM (publié à ICLR 2025) a mesuré que le routing intelligent entre un gros modèle et un petit peut réduire les coûts de 85% tout en gardant 95% de la qualité.
Les pièges
La tentation des 50 modèles. Tu peux configurer tous les modèles d'OpenRouter. En pratique, tu en utilises 3. Commence avec le strict minimum et ajoute selon tes besoins.
OpenRouter down = tout down. Si tu utilises OpenRouter comme unique backend et qu'il tombe, ton proxy ne sert plus à rien. Ajoute des accès directs aux providers critiques en fallback (on l'a vu dans la leçon précédente).
Le budget invisible. Les tokens s'accumulent vite, surtout avec des agents qui font des appels en boucle et des context windows qui grossissent. Mets des budgets sur tes virtual keys dès le départ.
La config qui dérive. Comme pour CLAUDE.md ou AGENTS.md, ta config LiteLLM évolue avec le temps. Versione-la dans Git.
Dans la prochaine leçon, on utilise LiteLLM directement depuis du code TypeScript avec le SDK OpenAI.
Sources :
- Simon Willison - OpenRouter posts
- Kate Soule, IBM Research - An air traffic controller for LLMs
- Denis Rasulev - OpenRouter vs LiteLLM: Choosing an LLM Gateway
- Isaac Ong et al. (UC Berkeley) - RouteLLM: Cost-Effective LLM Routing (ICLR 2025)
- Ihor Novytskyi - OpenRouter vs LiteLLM: features, pricing, and use cases
- Documentation LiteLLM
- Documentation OpenCode
- Elestio - LiteLLM Hosting